Кодировки utf-8 и windows 1251
Содержание:
Почему до сих пор используется 1251
Существует несколько причин, почему 1251 продолжает пользоваться большой популярностью среди разработчиков онлайн ресурсов:
- Многие программисты php используют стандартную кодировку, поскольку OC Windows ее поддерживает в режиме по умолчанию. И хотя в последнее время разработчики стали активно внедрять UTF-8, все же 1251 пока не сдает свои активные позиции
- Если брать для примера старую версию MySQL до четвертой, то стоит отметить, что при включении даже тестового режима, вылезало множество ошибок в UTF-8. Только после выпуска 4.1 многие «глюки» были исправлены. Существует категория программистов, которая вовсе остается верна 1251, а их последователи рьяно берут с них пример и даже не собираются использовать нечто другое
- Поскольку один символ в системе 1251 весит меньше (один байт), то вполне логично, что возникает некая экономия в отличие от последнего варианта.
По сравнению с данной кодировкой, UTF-8 считается более оптимальным вариантом, поскольку она может распознать большее количество символов.
- Возможно включение любых знаков из набора Юникода. Кроме того, вполне логично, что здесь поддерживается 100 000 символов против 256. Здесь можно найти от стандартных смайликов до апострофа абсолютно все. Их использование возможно в любом документе. Кроме того, их можно прочитать даже в редакторе, что исключает вероятность появления нечитабельных знаков
- Ранее существовало мнение о том, что современный utf занимает больше места. В итоге оказалось, что символы также весят всего лишь байт. Значит, стоит сделать вывод о том, что увеличение веса странички не происходит и ее использование такое же легкое. Однако, если используется только русский алфавит, то в таком случае размер будет увеличен вдвое, поскольку изначально кириллица не включена в систему
- Система считается одной из самых универсальных, которые уже смогли достать. В таком случае можно создавать сайты для любого населения мира. Можно уже не думать о том, какая кодировка используется, поскольку Юникод является универсальной вещью
- UTF – это оптимальный вариант работы с php страницами.
Важно отметить, что изначально многие разработчики стали использовать 1251. И хотя сейчас тенденции поменялись, последователей именно этой кодировки осталось, а значит она продолжает пользоваться большой популярностью среди пользователей.
И хотя сейчас тенденции поменялись, последователей именно этой кодировки осталось, а значит она продолжает пользоваться большой популярностью среди пользователей.
Кто-то считает, что универсальная utf – это неплохое решение, которое устанавливается для современных ресурсов, но 1251 – это проверенный алгоритм для стран, использующих кириллицу.
Стоит отметить, что в большинстве случаев используют автоматические переключение. Так, например, если понадобится прочитать информацию на иностранном языке или на русском, достаточно просто переключить кодировку на актуальный формат.
Вероятно, что в будущем 1251 станет еще меньше востребованной, а на смену придут новые проверенные системы. Однако сегодня многие все же используют именно ее.
Также важно принять на заметку, что для работы с utf знание английского языка является обязательным условием
Зачем нужна кодировка
Кодировка (Charset) — способ отображения кода на экране, соответствие набора символов набору числовых значений. О ней сообщает строка Content-Type и сервер в header запросе.
Студентка списывала реферат с формулами, а на сайте слетела кодировка. Реальная история
Google рекомендует всегда указывать сведения о кодировке, чтобы текст точно корректно отображался в браузере пользователя.
Кодировка влияет на SEO?
Разберемся, как кодировка на сайте влияет на индексацию в Яндекс и Google.
Яндекс четко заявляет:
Позиция Google такая же. Поисковики не рассматривают Charset как фактор ранжирования или сигнал для индексирования, тем не менее, она косвенно влияет на трафик и позиции.
Если кодировка сервера не совпадает с той, что указана на сайте, пользователи увидят нечитабельные символы вместо контента. На таком сайте сложно что-либо понять, так что скорее всего пользователи сбегут, а на сайте будут расти отказы.
Пример страницы со слетевшей кодировкой
Поэтому она важна для SEO, хоть и влияет на него косвенно через поведенческие. Пользователи должны видеть читабельный текст на человеческом языке, чтобы работать с сайтом.
Таблица кодировок ascii windows 1251
БлогNot. Таблица кодов кириллицы в Unicode, UTF-8 и Windows-1251
Таблица кодов кириллицы в Unicode, UTF-8 и Windows-1251
Во-первых, напомню, что Юникод – не кодировка, а стандарт кодирования, кодировки – это UTF-8, UTF-16 и т.д., но, в силу инерции, разработчики и пользователи часто говорят о “кодировке Юникод”, имея в виду распространённую именно в их деревне форму представления символов
Во-вторых, на самом деле кодирование там довольно замудрённое, возьмём, скажем русскую заглавную “Ж”.
Представляемые в Юникоде символы кодируются целыми числами без знака, их можно называть “кодами символов Unicode”.
Так, для буквы “Ж” Unicode = 104610 или 041616 или 10000 0101102. Unicode в двоичном виде разбивается на две части: пять левых бит и шесть правых. Левая часть в старших разрядах дополняется до байта признаком 110 двухбайтного кода UTF-8, получаем 11010000. К правой части в старших разрядах приписываются два бита 10 признака продолжения многобайтного кода, получаем 10010110. Окончательно код буквы “Ж” в UTF-8 будет иметь вид 11010000 100101102 или D0 9616.
Именно последний код мы увидим в любом 16-ричном вьюере файла, например, создав в текстовом редакторе файл со словом “Жора” и сохранив его в UTF-8 (только не из Блокнотика Windows, который добавит в начало файла 3-байтовую метку BOM):
То есть, каждая буква кодируется как бы дважды, сначала в 11-битный Unicode, затем в 16-битный UTF-8.
Ниже приведена таблица кодов кириллицы в Unicode, UTF-8 и однобайтовой кодировке Windows-1251.
| Символ | Unicode | UTF-8 | Windows-1251 | ||
|---|---|---|---|---|---|
| 16-ричн. | 10-тичн. | 16-ричн. | 10-тичн. | ||
| А | 0410 | 1040 | D090 | 208 144 | 192 |
| Б | 0411 | 1041 | D091 | 208 145 | 193 |
| В | 0412 | 1042 | D092 | 208 146 | 194 |
| Г | 0413 | 1043 | D093 | 208 147 | 195 |
| Д | 0414 | 1044 | D094 | 208 148 | 196 |
| Е | 0415 | 1045 | D095 | 208 149 | 197 |
| Ж | 0416 | 1046 | D096 | 208 150 | 198 |
| З | 0417 | 1047 | D097 | 208 151 | 199 |
| И | 0418 | 1048 | D098 | 208 152 | 200 |
| Й | 0419 | 1049 | D099 | 208 153 | 201 |
| К | 041A | 1050 | D09A | 208 154 | 202 |
| Л | 041B | 1051 | D09B | 208 155 | 203 |
| М | 041C | 1052 | D09C | 208 156 | 204 |
| Н | 041D | 1053 | D09D | 208 157 | 205 |
| О | 041E | 1054 | D09E | 208 158 | 206 |
| П | 041F | 1055 | D09F | 208 159 | 207 |
| Р | 0420 | 1056 | D0A0 | 208 160 | 208 |
| С | 0421 | 1057 | D0A1 | 208 161 | 209 |
| Т | 0422 | 1058 | D0A2 | 208 162 | 210 |
| У | 0423 | 1059 | D0A3 | 208 163 | 211 |
| Ф | 0424 | 1060 | D0A4 | 208 164 | 212 |
| Х | 0425 | 1061 | D0A5 | 208 165 | 213 |
| Ц | 0426 | 1062 | D0A6 | 208 166 | 214 |
| Ч | 0427 | 1063 | D0A7 | 208 167 | 215 |
| Ш | 0428 | 1064 | D0A8 | 208 168 | 216 |
| Щ | 0429 | 1065 | D0A9 | 208 169 | 217 |
| Ъ | 042A | 1066 | D0AA | 208 170 | 218 |
| Ы | 042B | 1067 | D0AB | 208 171 | 219 |
| Ь | 042C | 1068 | D0AC | 208 172 | 220 |
| Э | 042D | 1069 | D0AD | 208 173 | 221 |
| Ю | 042E | 1070 | D0AE | 208 174 | 222 |
| Я | 042F | 1071 | D0AF | 208 175 | 223 |
| а | 0430 | 1072 | D0B0 | 208 176 | 224 |
| б | 0431 | 1073 | D0B1 | 208 177 | 225 |
| в | 0432 | 1074 | D0B2 | 208 178 | 226 |
| г | 0433 | 1075 | D0B3 | 208 179 | 227 |
| д | 0434 | 1076 | D0B4 | 208 180 | 228 |
| е | 0435 | 1077 | D0B5 | 208 181 | 229 |
| ж | 0436 | 1078 | D0B6 | 208 182 | 230 |
| з | 0437 | 1079 | D0B7 | 208 183 | 231 |
| и | 0438 | 1080 | D0B8 | 208 184 | 232 |
| й | 0439 | 1081 | D0B9 | 208 185 | 233 |
| к | 043A | 1082 | D0BA | 208 186 | 234 |
| л | 043B | 1083 | D0BB | 208 187 | 235 |
| м | 043C | 1084 | D0BC | 208 188 | 236 |
| н | 043D | 1085 | D0BD | 208 189 | 237 |
| о | 043E | 1086 | D0BE | 208 190 | 238 |
| п | 043F | 1087 | D0BF | 208 191 | 239 |
| р | 0440 | 1088 | D180 | 209 128 | 240 |
| с | 0441 | 1089 | D181 | 209 129 | 241 |
| т | 0442 | 1090 | D182 | 209 130 | 242 |
| у | 0443 | 1091 | D183 | 209 131 | 243 |
| ф | 0444 | 1092 | D184 | 209 132 | 244 |
| х | 0445 | 1093 | D185 | 209 133 | 245 |
| ц | 0446 | 1094 | D186 | 209 134 | 246 |
| ч | 0447 | 1095 | D187 | 209 135 | 247 |
| ш | 0448 | 1096 | D188 | 209 136 | 248 |
| щ | 0449 | 1097 | D189 | 209 137 | 249 |
| ъ | 044A | 1098 | D18A | 209 138 | 250 |
| ы | 044B | 1099 | D18B | 209 139 | 251 |
| ь | 044C | 1100 | D18C | 209 140 | 252 |
| э | 044D | 1101 | D18D | 209 141 | 253 |
| ю | 044E | 1102 | D18E | 209 142 | 254 |
| я | 044F | 1103 | D18F | 209 143 | 255 |
| Символы вне общего правила | |||||
| Ё | 0401 | 1025 | D001 | 208 101 | 168 |
| ё | 0451 | 1105 | D191 | 209 145 | 184 |
23.09.2018, 12:37; рейтинг: 30317
Спасшая статья:
Приложение cmd.exe – это командная строка или программная оболочка с текстовым интерфейсом (во загнул ).
Запустить командную строку можно следующим способом: Пуск → Выполнить → вводим в поле команду – cmd и жмем ОК. В итоге откроется рабочее окно программы – c:WINDOWSsystem32cmd.exe. ( рис.1)
Если Вы занялись проблемой кодировки шрифтов в cmd.exe , то как запускать командную строку наверняка уже знаете
Перейдем собственно к проблеме: иногда вместо русских букв при выполнении команд выходит набор непонятных символов ( рис.2).
Первым делом нужно зайти в свойства окна – правой кнопкой щелкнуть по верхней части окна → Свойства → выйдет окно рис.3, здесь в поле Шрифтвыбираем Luc >ОК.
Теперь Вы получили нормальный текст на русском языке. Так же можно поменять текущую кодировку шрифта, для этого используется команда chcp. Набираем эту команду и жмем Enter, в результате получим текущую кодировку для командной строки – рис.4.
Для изменения кодировки так же применим chcp в следующем формате:
Где – это цифровой параметр нужного шрифта, например,
1251 – Windows (кириллица);
Выбирайте на любой вкус. Т.о. что бы изменить кодировку на UTF-8 нужно выполнить команду chcp 65001.
almixРазработчик Loco, автор статей по веб-разработке на Yii, CodeIgniter, MODx и прочих инструментах. Создатель Team Sense.
Как корректно отобразить Русский текст в CMD. Проблемы с кодировкой могут возникнуть, например, при выполнении Bat файла, когда нужно вывести в консоль русский текст и при других обстоятельствах, о которых речь пойдёт далее.
Рассмотрим пример: когда нужно вывести в консоль Русский текст, скажем «Примет мир». Для этого создадим Bat файл с именем «1.bat». Используйте для этого обычный Блокнот Windows (Notepad.exe) Запишем в него следующие строки!
Для тех, кто не понял или не в курсе, строчки «echo.» я добавил специально, что бы были отступы, от строки «Примет мир»
Теперь запускаем файл 1.bat и результат будет такого вида.
Как видим проблема с кодировкой в cmd на лицо. И произошло это по следующей причине.
Стандартный блокнот Windows сохранил Bat файл в кодировке «1251» а консоль вывела его в кодировки «866». Вот от сюда все проблемы!
Таблицы
Нижняя часть таблицы кодировки (латиница) полностью соответствует кодировке Юникоде.
Кодировка Windows-1251 (синоним CP1251)
| . | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8. | Ђ 402 | Ѓ 403 | ‚ 201A | ѓ 453 | „ 201E | … 2026 | † 2020 | ‡ 2021 | € 20AC | ‰ 2030 | Љ 409 | ‹ 2039 | Њ 40A | Ќ 40C | Ћ 40B | Џ 40F |
| 9. | ђ 452 | ‘ 2018 | ’ 2019 | “ 201C | ” 201D | • 2022 | – 2013 | — 2014 | 2122 | љ 459 | › 203A | њ 45A | ќ 45C | ћ 45B | џ 45F | |
| A. | A0 | Ў 40E | ў 45E | Ј 408 | ¤ A4 | Ґ 490 | ¦ A6 | § A7 | Ё 401 | A9 | Є 404 | « AB | ¬ AC | AD | AE | Ї 407 |
| B. | ° B0 | ± B1 | І 406 | і 456 | ґ 491 | µ B5 | ¶ B6 | · B7 | ё 451 | № 2116 | є 454 | » BB | ј 458 | Ѕ 405 | ѕ 455 | ї 457 |
| C. | А 410 | Б 411 | В 412 | Г 413 | Д 414 | Е 415 | Ж 416 | З 417 | И 418 | Й 419 | К 41A | Л 41B | М 41C | Н 41D | О 41E | П 41F |
| D. | Р 420 | С 421 | Т 422 | У 423 | Ф 424 | Х 425 | Ц 426 | Ч 427 | Ш 428 | Щ 429 | Ъ 42A | Ы 42B | Ь 42C | Э 42D | Ю 42E | Я 42F |
| E. | а 430 | б 431 | в 432 | г 433 | д 434 | е 435 | ж 436 | з 437 | и 438 | й 439 | к 43A | л 43B | м 43C | н 43D | о 43E | п 43F |
| F. | р 440 | с 441 | т 442 | у 443 | ф 444 | х 445 | ц 446 | ч 447 | ш 448 | щ 449 | ъ 44A | ы 44B | ь 44C | э 44D | ю 44E | я 44F |
Кодировка CP1251-k (KazWin, казахская кодировка)
| . | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8. | Ұ 4B0 | Ғ 492 | ‚ 201A | ғ 493 | „ 201E | … 2026 | † 2020 | ‡ 2021 | € 20AC | ‰ 2030 | Ө 4E8 | ‹ 2039 | Ң 4A2 | Қ 49A | Һ 4BA | Ү 4AE |
| 9. | ұ 4B1 | ‘ 2018 | ’ 2019 | “ 201C | ” 201D | • 2022 | – 2013 | — 2014 | 2122 | ө 4E9 | › 203A | ң 4A3 | қ 49B | һ 4BB | ү 4AF | |
| A. | A0 | Ў 40E | ў 45E | Җ 496 | ¤ A4 | Ҳ 4B2 | ¦ A6 | § A7 | Ё 401 | A9 | Є 404 | « AB | ¬ AC | AD | AE | Ї 407 |
| B. | ° B0 | ± B1 | І 406 | і 456 | ҳ 4B3 | µ B5 | ¶ B6 | · B7 | ё 451 | № 2116 | є 454 | » BB | җ 497 | Ә 4D8 | ә 4D9 | ї 457 |
Кодировка Windows-1251 (чувашский вариант)
| . | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8. | Ђ 402 | Ѓ 403 | ‚ 201A | ѓ 453 | „ 201E | … 2026 | † 2020 | ‡ 2021 | € 20AC | ‰ 2030 | Љ 409 | ‹ 2039 | Ӑ 4D0 | Ӗ 4D6 | Ҫ 4AA | Ӳ 4F2 |
| 9. | ђ 452 | ‘ 2018 | ’ 2019 | “ 201C | ” 201D | • 2022 | – 2013 | — 2014 | 2122 | љ 459 | › 203A | ӑ 4D1 | ӗ 4D7 | ҫ 4AB | ӳ 4F3 |
Татарский вариант
Эта кодировка была официально принята в Татарстане в 1996 г.
| . | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8. | Ә 4D8 | Ѓ 403 | ‚ 201A | ѓ 453 | „ 201E | … 2026 | † 2020 | ‡ 2021 | € 20AC | ‰ 2030 | Ө 4E8 | ‹ 2039 | Ү 4AE | Җ 496 | Ң 4A2 | Һ 4BA |
| 9. | ә 4D9 | ‘ 2018 | ’ 2019 | “ 201C | ” 201D | • 2022 | – 2013 | — 2014 | 2122 | ө 4E9 | › 203A | ү 4AF | җ 497 | ң 4A3 | һ 4BB |
Кодировки UTF-8 и Windows 1251 — просто о сложном

Здравствуйте, уважаемые читатели моего блога. Сегодня мы поговорим с вами про кодировку. Если вы читали мою статью о том, как посмотреть код страницы в браузере, то знаете, что любой документ в интернете хранится не в том виде, в каком мы привыкли его видеть. Он записан при помощи непонятных человеку символов и знаков. С текстом все точно также.
Существует несколько кодировок, а потому, иногда увидев непонятные символы при открытии книги в мобильном приложении или запилив статью на сайт, вы, поменяв кое-какие значения в настройках, увидите привычный глазу алфавит.

Кодировка windows-1251 – что это такое, какое значение она имеет при создании сайта, какие символы будут доступны и является ли она лучшим решением на сегодняшний день? Обо всем этом в сегодняшней статье. Как всегда, простым языком, максимально понятно и с минимальным количеством терминов.
Базы банных
Когда речь идет о php, все вообще страшно. Я уже рассказывал про базы данных, они используются для ускорения работы сайта. Обычно, вы к ним не обращаетесь, но когда появляется необходимость в переносе сайта становится не по себе.
Сложности случаются у всех, не важно какой у вас опыт работы, стаж и выслуга лет. Некоторые странички в базе могут содержать в себе все доступные символы для виндовс-1251, другие, к примеру, в шаблонах страниц, в другой кодировке
Пока не нужен перенос все работает и функционирует, хоть и не совсем правильно. Но после переезда начинаются неприятности. В идеале вы должны использовать либо только УТФ, либо виндовс-1251, но по факту всегда и у всех случаются вот такие недочеты.
Чтобы расшифровка согласовалась необходимо вписать код mysql_query(«SET NAMES cp1251»). В этом случае преобразование будет осуществлять по другому протоколу – cp1251.
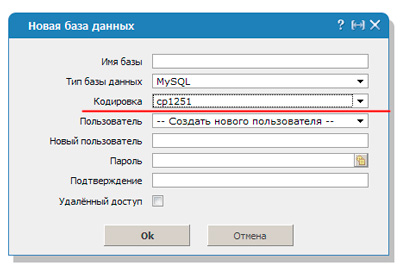
Базы банных
Когда речь идет о php, все вообще страшно. Я уже рассказывал про базы данных, они используются для ускорения работы сайта. Обычно, вы к ним не обращаетесь, но когда появляется необходимость в переносе сайта становится не по себе.
Сложности случаются у всех, не важно какой у вас опыт работы, стаж и выслуга лет. Некоторые странички в базе могут содержать в себе все доступные символы для виндовс-1251, другие, к примеру, в шаблонах страниц, в другой кодировке
Пока не нужен перенос все работает и функционирует, хоть и не совсем правильно. Но после переезда начинаются неприятности. В идеале вы должны использовать либо только УТФ, либо виндовс-1251, но по факту всегда и у всех случаются вот такие недочеты.
Чтобы расшифровка согласовалась необходимо вписать код mysql_query(«SET NAMES cp1251»). В этом случае преобразование будет осуществлять по другому протоколу – cp1251.
Исправляем отображение русских букв в Windows 10
Существует два способа решения рассматриваемой проблемы. Связаны они с редактированием настроек системы или определенных файлов. Они отличаются по сложности и эффективности, поэтому мы начнем с легкого. Если первый вариант не принесет никакого результата, переходите ко второму и внимательно следуйте описанным там инструкциям.
Способ 1: Изменение языка системы
В первую очередь хотелось бы отметить такую настройку как «Региональные стандарты». В зависимости от его состояния и производится дальнейшее отображение текста во многих системных и сторонних программах. Редактировать его под русский язык можно следующим образом:
- Откройте меню «Пуск» и в строке поиска напечатайте «Панель управления». Кликните на отобразившийся результат, чтобы перейти к этому приложению.
Среди присутствующих элементов отыщите «Региональные стандарты» и нажмите левой кнопкой мыши на этот значок.
Появится новое меню с несколькими вкладками. В данном случае вас интересует «Дополнительно», где нужно кликнуть на кнопку «Изменить язык системы…».
Корректировки вступят в силу только после перезагрузки ПК, о чем вы и будете уведомлены при выходе из меню настроек.
Дождитесь перезапуска компьютера и проверьте, получилось ли исправить проблему с русскими буквами. Если нет, переходите к следующему, более сложному варианту решения этой задачи.
Способ 2: Редактирование кодовой страницы
Кодовые страницы выполняют функцию сопоставления символов с байтами. Существует множество разновидностей таких таблиц, каждая из которых работает с определенным языком. Часто причиной появления кракозябров является именно неправильно выбранная страница. Далее мы расскажем, как править значения в редакторе реестра.
- Нажатием на комбинацию клавиш Win + R запустите приложение «Выполнить», в строке напечатайте regedit и кликните на «ОК».
- В окне редактирования реестра находится множество директорий и параметров. Все они структурированы, а необходимая вам папка расположена по следующему пути:
Выберите «CodePage» и опуститесь в самый низ, чтобы отыскать там имя «ACP». В столбце «Значение» вы увидите четыре цифры, в случае когда там выставлено не 1251, дважды кликните ЛКМ на строке.
Двойное нажатие левой кнопкой мыши открывает окно изменения строковой настройки, где и требуется выставить значение 1251 .
Если же значение и так уже является 1251, следует провести немного другие действия:
- В этой же папке «CodePage» поднимитесь вверх по списку и отыщите строковый параметр с названием «1252» Справа вы увидите, что его значение имеет вид с_1252.nls. Его нужно исправить, поставив вместо последней двойки единицу. Дважды кликните на строке.
Откроется окно редактирования, в котором и выполните требуемую манипуляцию.
После завершения работы с редактором реестра обязательно перезагрузите ПК, чтобы все корректировки вступили в силу.
Подмена кодовой страницы
Некоторые пользователи не хотят править реестр по определенным причинам либо же считают эту задачу слишком сложной. Альтернативным вариантом изменения кодовой страницы является ее ручная подмена. Производится она буквально в несколько действий:
- Откройте «Этот компьютер» и перейдите по пути C:\Windows\System32 , отыщите в папке файл С_1252.NLS, кликните на нем правой кнопкой мыши и выберите «Свойства».
Переместитесь во вкладку «Безопасность» и найдите кнопку «Дополнительно».
Вам нужно установить имя владельца, для этого кликните на соответствующую ссылку вверху.
В пустом поле впишите имя активного пользователя, обладающего правами администратора, после чего нажмите на «ОК».
Вы снова попадете во вкладку «Безопасность», где требуется откорректировать параметры доступа администраторов.
Выделите ЛКМ строку «Администраторы» и предоставьте им полный доступ, установив галочку напротив соответствующего пункта. По завершении не забудьте применить изменения.
Вернитесь в открытую ранее директорию и переименуйте отредактированный файл, поменяв его расширение с NLS, например, на TXT. Далее с зажатым CTRL потяните элемент «C_1251.NLS» вверх для создания его копии.
Нажмите на созданной копии правой кнопкой мыши и переименуйте объект в C_1252.NLS.
Вот таким нехитрым образом происходит подмена кодовых страниц. Осталось только перезапустить ПК и убедиться в том, что метод оказался эффективным.
Как видите, исправлению ошибки с отображением русского текста в операционной системе Windows 10 способствуют два достаточно легких метода. Выше вы были ознакомлены с каждым. Надеемся, предоставленное нами руководство помогло справиться с этой неполадкой.
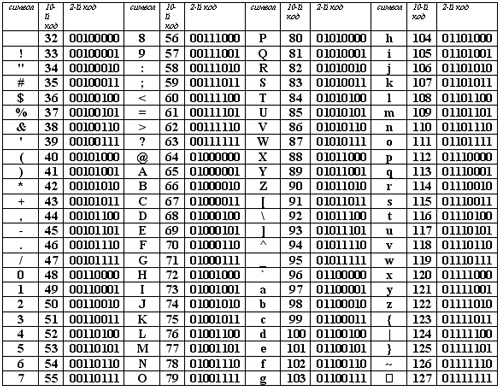
Базовая таблица кодировки ASCII
| 32 пробел | 48 0 | 64 @ | 80 P | 96 ` | 112 p |
| 33 ! | 49 1 | 65 A | 81 Q | 97 a | 113 q |
| 34 “ | 50 2 | 66 B | 82 R | 98 b | 114 r |
| 35 # | 51 3 | 67 C | 83 S | 99 c | 115 s |
| 36 $ | 52 4 | 68 D | 84 T | 100 d | 116 t |
| 37 % | 53 5 | 69 E | 85 U | 101 e | 117 u |
| 38 & | 54 6 | 70 F | 86 V | 102 f | 118 v |
| 39 ‘ | 55 7 | 71 G | 87 W | 103 g | 119 w |
| 40 ( | 56 8 | 72 H | 88 X | 104 h | 120 x |
| 41 ) | 57 9 | 73 I | 89 Y | 105 i | 121 y |
| 42 * | 58 : | 74 J | 90 Z | 106 j | 122 z |
| 43 + | 59 ; | 75 K | 91 [ | 107 k | 123 { |
| 44 , | 60 < | 76 L | 92 \ | 108 l | 124 | |
| 45 — | 61 = | 77 M | 93 ] | 109 m | 125 } |
| 46 . | 62 > | 78 N | 94 ^ | 110 n | 126 ~ |
| 47 / | 63 ? | 79 O | 95 _ | 111 o | 127 |
Символы с номерами от 128 до 255 представляют собой таблицу расширения и варьируются в зависимости от набора скриптов, представленных кодировкой символов. Набор символов таблицы расширения различается в зависимости от выбранной кодовой страницы:
Базы банных
Когда речь идет о php, все вообще страшно. Я уже рассказывал про базы данных, они используются для ускорения работы сайта. Обычно, вы к ним не обращаетесь, но когда появляется необходимость в переносе сайта становится не по себе.
Сложности случаются у всех, не важно какой у вас опыт работы, стаж и выслуга лет. Некоторые странички в базе могут содержать в себе все доступные символы для виндовс-1251, другие, к примеру, в шаблонах страниц, в другой кодировке
Пока не нужен перенос все работает и функционирует, хоть и не совсем правильно. Но после переезда начинаются неприятности. В идеале вы должны использовать либо только УТФ, либо виндовс-1251, но по факту всегда и у всех случаются вот такие недочеты.
Чтобы расшифровка согласовалась необходимо вписать код mysql_query(«SET NAMES cp1251»). В этом случае преобразование будет осуществлять по другому протоколу – cp1251.
Немного из истории
С наступлением 90-х годов, после распада СССР, границы России стали открыты.
Поэтому на территорию страны стало постепенно проникать оборудование из европейских стран.
Изначально все они были запрограммированы на английском языке.
В этот же промежуток времени начинает активно распространяться интернет.
В результате стало необходимо как можно быстрее русифицировать все оборудование и программное обеспечение. В связи с данной необходимостью появилась кодировка 1251. С ее помощью на компьютерах корректно отображаются славянские буквы алфавита.
А значит стало возможным использовать компьютеры со следующими языками:
- Русский
- Белорусский
- Украинский
- Сербский
- Болгарский
- Македонский.
Совместно с двумя российскими компаниями «Параграф» и «Диалог», представительства компании Microsoft начали активно заниматься разработкой данной кодировки.
В качестве основы были использованы обыкновенные самостоятельно написанные разработки.
Однако технический прогресс не стоит на месте, поэтому в последнее время широкое применение нашел Юникод UTF-8.
В него заложено порядком 90% web-ресурсов. Что касается 1251, то она используется менее, чем в 2%.
Немного теории
Любой документ на компьютере или в интернете, как я уже сказал, хранится в виде двоичного кода. К примеру, если вы используете кодировку ASCII, то буква «К» будет записана как 10001010, а windows 1251 под этим числом скрывается символ – Љ. В итоге, если браузер или программа обратится к другой таблице и считает вместо ASCII коды windows 1251, то читатель увидит совершенно непонятные ему символ.
Логичен вопрос, нафига было придумывать множество таблиц с кодами? Дело в том, что помимо русского алфавита существует еще и английский, немецкий, китайский. По некоторым подсчетам, существует около 200 000 символов. Хотя, я не очень доверяю этой статистике, вспоминая про японский.
Не забывайте, что для заглавной и строчной буквы нужно придумать свой код, есть запятые, тире и так далее.
Чем больше в таблице символов, тем длиннее код каждого из них, а значит и вес документа становится больше.
Представьте, если бы одна книга весила 4 Гб! Она бы очень долго загружалась, занимала все свободное место на компьютере. Решение о скачивании представлялось бы делом нелегким.
Если вспомнить о сайтах, то вообще страшно подумать, что бы произошло. Каждая страничка открывалась даже на скоростном оптоволокне по часу с лишним! Думаю, мобильные телефоны можно было бы смело выкидывать. Пользоваться ими на улице даже с 4G? Сомневаюсь.
По этим причинам каждый программист в свое время старался придумать свою таблицу символов. Чтобы было удобно для использования и вес сохранялся оптимальным.
Microsoft, к примеру, для русскоязычного сегмента создали windows-1251. В ней, конечно же, есть свои достоинства и недостатки. Как и у любого другого продукта.
Сейчас уже, лишь 2% всех страниц в интернете написано на 1251. Большинство веб-мастеров используют UTF-8. Почему так?
Работа с картами 1С 4 в 1: Яндекс, Google , 2ГИС, OpenStreetMap(OpenLayers) Промо
С каждым годом становится все очевидно, что использование онлайн-сервисов намного упрощает жизнь. К сожалению по картографическим сервисам условия пока жестковаты. Но, ориентируясь на будущее, я решил показать возможности API выше указанных сервисов:
Инициализация карты
Поиск адреса на карте с текстовым представлением
Геокодинг
Обратная поиск адреса по ее координатами
Взаимодействие с картами — прием координат установленного на карте метки
Построение маршрутов по указанным точками
Кластеризация меток на карте при увеличении масштаба
Теперь также поддержка тонкого и веб-клиента
1 стартмани
Инструкция по восстановлению кодировки
Ситуация, когда в командной строке присутствуют непонятные символы, вопросительные знаки или иероглифы довольна распространенная.
Однако исправить положение возможно самостоятельно, не прибегая к помощи специалистов.
Сразу стоит отметить, что это первый признак того, что в седьмом Windows слетела кодировка 1251.
С восьмой версии активно используют UTF-8.
Для того, чтобы решить задачу максимально быстро, возможно использование команды CHCP 866, но это только временная мера и в полной мере проблему она не решит.
Как правило, реестр используется для основательного решения проблемы:
Как исправить иероглифы Windows 10 путем изменения кодовых страниц
Кодовые страницы представляют собой таблицы, в которых определенным байтам сопоставляются определенные символы, а отображение кириллицы в виде иероглифов в Windows 10 связано обычно с тем, что по умолчанию задана не та кодовая страница и это можно исправить несколькими способами, которые могут быть полезны, когда требуется не изменять язык системы в параметрах.
С помощью редактора реестра
Первый способ — использовать редактор реестра. На мой взгляд, это самый щадящий для системы метод, тем не менее, рекомендую создать точку восстановления прежде чем начинать. Совет про точки восстановления относится и ко всем последующим способам в этом руководстве.
Обычно, это исправляет проблему с отображением русских букв. Вариация способа с помощью редактора реестра (но менее предпочтительная) — посмотреть на текущее значение параметра ACP (обычно — 1252 для изначально англоязычных систем), затем в том же разделе реестра найти параметр с именем 1252 и изменить его значение с c_1252.nls на c_1251.nls.

Путем подмена файла кодовой страницы на c_1251.nls
Второй, не рекомендуемый мной способ, но иногда выбираемый теми, кто считает, что правка реестра — это слишком сложно или опасно: подмена файла кодовой страницы в C:\ Windows\ System32 (предполагается, что у вас установлена западно-европейская кодовая страница — 1252, обычно это так. Посмотреть текущую кодовую страницу можно в параметре ACP в реестре, как было описано в предыдущем способе).
После перезагрузки Windows 10 кириллица должна будет отображаться не в виде иероглифов, а как обычные русские буквы.
Неправильная кодировка результатов из базы данных MySQL
Если ваш сайт состоит из статической части (шаблон) и динамической, которая формируется из данных, получаемых из базы данных, то может возникнуть ситуация, когда часть сайта имеет правильную кодировку, а другая часть сайта имеет неправильную. В этом случае бесполезно менять настройки веб-сервера – поскольку всё равно часть страницы будет иметь неправильную кодировку.
Нужно начать с определения кодировки ваших таблиц. Можно посмотреть в phpMyAdmin:

Обратите внимание на столбец «Сравнение», запись «utf8_unicode_ci» означает, что используется кодировка UTF-8. Можно подключиться к СУБД MySQL и проверить кодировку таблиц без phpMyAdmin
Для этого:
Можно подключиться к СУБД MySQL и проверить кодировку таблиц без phpMyAdmin. Для этого:
Если вы забыли имя базы данных, то выполните команду:
Предположим, я хочу посмотреть кодировку для таблиц в базе данных information_schema
Если вы забыли имя таблиц, выполните:
Далее выполните команду, в которой имя_таблицы замените на настоящее имя таблицы:
Вы увидите примерно следующее:

Смотрите столбец Collation. В моём случае там utf8_general_ci, это, как и utf8_unicode_ci, кодировка UTF-8. Кстати, если вы не знаете в чём разница между кодировками utf8_general_ci, utf8_unicode_ci, utf8mb4_general_ci, utf8mb4_unicode_ci, а также какую кодировку выбрать для базы данных MySQL, то посмотрите эту статью.
Теперь, когда мы узнали кодировку (в моём случае это UTF-8), то при каждом подключении к СУБД MySQL нужно выполнять последовательно запросы:
В PHP это можно сделать примерно так:
Обратите внимание, что UTF8 вам нужно заменить на ту кодировку, которая используется для ваших таблиц
Кракозябры вместо русских букв — как исправить
Давайте теперь посмотрим, как появляются вместо текста кракозябры или, другими словами, как выбирается правильная кодировка для русского текста. Собственно, она задается в той программе, в которой вы создаете или редактируете этот самый текст, или же код с использованием текстовых фрагментов.
В верхнем меню Notepad++ есть пункт «Кодировки», где у вас будет возможность преобразовать уже имеющийся вариант в тот, который используется на вашем сайте по умолчанию:

Дело в том, что когда разрабатывали кодировку ЮТФ-16, зачем-то решили прикрутить к ней такую вещь, как возможность записывать код символа, как в прямой последовательности (например, 0A15), так и в обратной (150A). А для того, чтобы программы понимали, в какой именно последовательности читать коды, и был придуман BOM (Byte Order Mark или, другими словами, сигнатура), которая выражалась в добавлении трех дополнительных байтов в самое начало документов.
Что примечательно, некоторые программы в Windows не умеют этого делать (не умеют сохранять текст в ЮТФ-8 без BOM), например, все тот же пресловутый Блокнот Windows. Он сохраняет документ в UTF-8, но все равно добавляет в его начало сигнатуру (три дополнительных байта). Причем эти байты будут всегда одни и те же — читать код в прямой последовательности. Но на серверах из-за этой мелочи может возникнуть проблема — вылезут кракозябры.
Поэтому ни в коем случае не пользуйтесь обычным блокнотом Windows для редактирования документов вашего сайта, если не хотите появления кракозябров. Лучшим и наиболее простым вариантом я считаю уже упомянутый редактор Notepad++, который практически не имеет недостатков и состоит из одних лишь достоинств.
В Notepad ++ при выборе кодировки у вас будет возможность преобразовать текст в кодировку UCS-2, которая по своей сути очень близка к стандарту Юникод. Также в Нотепаде можно будет закодировать текст в ANSI, т.е. применительно к русскому языку это будет уже описанная нами чуть выше Windows 1251. Откуда берется эта информация?
Она прописана в реестре вашей операционной системы Windows — какую кодировку выбирать в случае ANSI, какую выбирать в случае OEM (для русского языка это будет CP866). Если вы установите на своем компьютере другой язык по умолчанию, то и эти кодировки будут заменены на аналогичные из разряда ANSI или OEM для того самого языка.
После того, как вы в Notepad++ сохраните документ в нужной вам кодировке или же откроете документ с сайта для редактирования, то в правом нижнем углу редактора сможете увидеть ее название:

Вообще, во всех языках гипертекстовой разметки кроме Html используется специальное объявление xml, в котором указывается кодировка текста.
Прежде, чем начать разбирать код, браузер узнает, какая версия используется и как именно нужно интерпретировать коды символов этого языка. Но что примечательно, в случае, если вы сохраняете документ в принятом по умолчанию юникоде, то это объявление xml можно будет опустить (кодировка будет считаться UTF-8, если нет BOM или ЮТФ-16, если BOM есть).
Эта запись довольно сильно отличается от принятой в стандарте в Html 4.01, но полностью соответствует новому внедряемому потихоньку стандарту Html 5, и она будет стопроцентно правильно понята любыми используемыми на текущий момент браузерами.
Создание договоров по шаблонам Word в УТ 11.2, БП 3.0 с возможностью хранения в справочнике «Файлы»
Публикация предназначена тем, кто ведет договоры в УТ 11 не только в справочнике «Договоры с контрагентами», но также формирует и согласовывает с контрагентами договоры в формате Word (*.doc). А так как программисты люди ленивые и я не являюсь исключением в этом (хорошем) смысле :), была создана эта печатная форма. Но это не простая печатная форма, а инструмент, который позволяет на основании шаблона, хранящегося в информационной базе в справочнике «Файлы», быстро заполнять и сохранять тут же в справочник «Файлы», но в другую папку, уже заполненный на основании шаблона договор в формате Word.
10 стартмани








