Csv файл: что это такое?
Содержание:
- Способ 4. FileHelpers (https://www.filehelpers.net)
- Writer Objects¶
- Импорт из папки
- Таблица сравнения результатов
- Резюме файла CSV
- Модули для чтения и записи
- Добавление в запрос новых файлов и обновление сводной таблицы
- Диалекты и параметры форматирования¶
- Как структурированы csv файлы
- С чего начать
- Чтение¶
- Важная информация о редактировании файлов csv
- Онлайн конвертер CSV
- Как преобразовать файл Excel в CSV
- Чтение файла CSV
- Импорт данных из файлов с разделителями-запятыми
Способ 4. FileHelpers (https://www.filehelpers.net)
Данная библиотека не умеет обрабатывать CSV отдельно по строкам, вместо этого она пытается загрузить весь файл в объект, который должен быть заранее описан в виде отдельного класса или структуры. В связи с этими недостатками, библиотека показала самые худшие результаты обработки больших CSV файлов. FileHelpers не только самая медленная, но еще и очень сильно потребляет память, а диагностика нам показывает, что сборщик мусора вызывается постоянно.
На картинке ниже сравниваем способы 2 (слева) и 4 (справа):
Обратите внимание на график Process Memory, на желтые флажки, которые означают запуск сборки мусора. Слева всего 6 раз вызывается GC, а справа бесчисленное количество раз, что сказывается на производительности
При обработке файла размером 795Мб сначала тест провалился. Во первых, нехватает памяти, во-вторых начинает работать процесс «Отчет об ошибках Windows»
Чтобы избежать нехватки памяти добавил принудительный вызов сбора мусора:
После этого тест прошел и я увидел, что данный способ для обработки файла 795 Мб требуется в 10 раз больше памяти.
Writer Objects¶
objects ( instances and objects returned by
the function) have the following public methods. A row must be
an iterable of strings or numbers for objects and a dictionary
mapping fieldnames to strings or numbers (by passing them through
first) for objects. Note that complex numbers are written
out surrounded by parens. This may cause some problems for other programs which
read CSV files (assuming they support complex numbers at all).
- (row)
-
Write the row parameter to the writer’s file object, formatted according to
the current dialect. Return the return value of the call to the write method
of the underlying file object.Changed in version 3.5: Added support of arbitrary iterables.
- (rows)
-
Write all elements in rows (an iterable of row objects as described
above) to the writer’s file object, formatted according to the current
dialect.
Writer objects have the following public attribute:
-
A read-only description of the dialect in use by the writer.
DictWriter objects have the following public method:
Импорт из папки
Источником в Power Query могут быть не только отдельные файлы, но и целая папка со всем ее содержимым. Далее дело следующей техники.
Создадим папку Данные о продажах csv и поместим в нее сразу три файла за январь, февраль и март. Сделаем запрос к этой папке Данные – Скачать и преобразовать – Создать запрос – Из папки. В следующем окне указываем путь. Адрес лучше заранее скопировать и затем вставить, чем искать в проводнике. В редакторе Power Query мы увидим такую таблицу.
Выглядит подозрительно, т.к. вместо данных что-то непонятное. Действительно, сейчас видны только файлы, содержащиеся в папке, и информация о них: название, расширение, время создания, изменения и т.д. Переходим к извлечению данных из этих файлов.
Следующий шаг не является обязательным, но он позволит избежать некоторых возможных проблем в будущем. Нужно понимать, что все содержимое указанной папки будет извлечено с помощью запроса Power Query. И если туда попадет какой-нибудь, например, файл Excel, то запрос «поломается» и выдаст ошибку. Поэтому опытные пользователи создают «защиту», чтобы файлы с другим расширением отфильтровывались.
Идея в том, чтобы в столбце Extension поставить фильтр на расширение .csv. Чтобы случайно не отфильтровать файлы .CSV, сделаем все буквы для столбца Extension маленькими. Для этого выделяем столбец, далее через правую кнопку мыши Преобразование – нижний регистр. Переходим к установке фильтра. Если в выпадающем списке фильтра поставить переключатель на значение .csv, то у нас ничего не получится, т.к. при единственном типе файлов будет автоматически выделен пункт Выбрать все. Поэтому выбираем Текстовые фильтры – Равно… и указываем .csv (обязательно с точкой впереди).
Теперь случайное добавление в указанную папку файлов Excel не повлияет на работу запроса. Этот шаг, повторюсь, необязательный, но лучше прислушаться к совету опытных пользователей.
Приступим к извлечению данных. Содержимое файлов скрыто в колонке Content за значением Binary.
Перед тем, как развернуть содержимое этого столбца, избавимся от лишней информации. Выделяем столбец Content и через правую кнопку мыши выбираем Удалить другие столбцы.
Наступило время сеанса магии с разоблачением. В верхнем правом углу находится кнопка с двумя стрелками, направленными вниз.
Это кнопка загрузки двоичного (бинарного) файла. Жмем. И о чудо! Содержимое всех трех файлов один за другим выгружается в единую таблицу.
Однако на этот раз потребуется вручную внести некоторые корректировки.
• Удалим последний шаг Измененный тип
• Преобразование – Использовать первую строку в качестве заголовков
• Правой кнопкой мыши по полю Дата – Тип изменения – Дата
• Удерживая Shift, выделяем два столбца Наименование и Менеджер, затем через правую клавишу мыши Тип изменения – Текст
• Через Shift выделяем остальные столбцы Цена, Стоимость, Комиссия – правая клавиши мыши – Тип изменения – Десятичное число
• Правой кнопкой мыши по полю Дата – Удалить ошибки
• Главная – Закрыть – Закрыть и загрузить
Таким образом, мы получаем таблицу с единым заголовком, сделанную из трех файлов. На ее основе создадим сводную таблицу.
Сводная таблица построена по 116 строкам. Таким же образом можно было бы объединить и 10 файлов с сотнями тысяч строк.
Таблица сравнения результатов
Тесты проводились на двух файлах. Первый файл слева (до знака /), второй файл справа (после знака /):
размер файла — 557 Мб / 795 Мб
количество строк — 4 496 263 / 3 697 693
количество полей 44 / 32
Способ Multiline Csv Reader реализован в моем приложении ImportExportDataSql, который использует класс System.IO.StreamReader метод ReadLine (в таблице мой метод до оптимизации кода) и он немного быстрее метода Split().
|
Multiline Csv Reader |
StreamReader (Split) |
|||||||
|
original |
inline |
|||||||
|
AVG elapsed (ms) |
5307 / 5682 |
5527 / 6034 |
2404 / 5096 |
59402 / 32909 |
21872 / 14697 |
3630 / 4005 |
4998 / 5293 |
24633 / 19396 |
|
MAX elapsed (ms) |
5599 / 5778 |
6040 / 6165 |
2585 / 5162 |
71378 / 34788 |
24103 / 15827 |
3775 / 4099 |
5781 / 6189 |
28513 / 22531 |
|
AVG Memory usage (KB) |
32713 / 29693 |
31452 / 30182 |
32161 / 30963 |
4842975/ 3642521 |
4287987 / 2939645 |
30914 / 29935 |
439530 / 457219 |
36011 / 35523 |
|
MAX Memory usage (KB) |
35684 / 30652 |
33480 / 30428 |
35956 / 33848 |
9409732/ 7232620 |
8307932 / 5644120 |
33352 / 32116 |
841908 / 843816 |
38576 / 39448 |
|
AVG CPU usage (%) |
12 / 12 |
11 / 15 |
10 / 14 |
12 / 12 |
13 / 12 |
11 / 18 |
12 / 13 |
12 / 12 |
Резюме файла CSV
Расширение файла CSV включает в себя один основных типов файлов и его можно открыть с помощью Microsoft Excel (разработчик — Microsoft Corporation). В общей сложности с этим форматом связано всего одиннадцать программное (-ых) обеспечение (-я). Чаще всего они имеют тип формата Comma Separated Values File.
Чаще всего файлы CSV классифицируют, как Data Files.
Просматривать файлы CSV можно с помощью операционных систем Windows, Mac и iOS. Они обычно находятся на настольных компьютерах (и ряде мобильных устройств) и позволяют просматривать и иногда редактировать эти файлы.
Рейтинг популярности файлов CSV составляет «Низкий». Это означает, что они не часто встречаются на большинстве устройств.
Модули для чтения и записи
Модуль CSV имеет несколько функций и классов, доступных для чтения и записи CSV, и они включают в себя:
- функция csv.reader
- функция csv.writer
- класс csv.Dictwriter
- класс csv.DictReader
csv.reader
Модуль csv.reader принимает следующие параметры:
- : обычно это объект, который поддерживает протокол итератора и обычно возвращает строку каждый раз, когда вызывается его метод .
- : необязательный параметр, используемый для определения набора параметров, специфичных для определенного диалекта CSV.
- : необязательный параметр, который можно использовать для переопределения существующих параметров форматирования.
Вот пример того, как использовать модуль csv.reader.
модуль csv.writer
Этот модуль похож на модуль csv.reader и используется для записи данных в CSV. Требуется три параметра:
- : это может быть любой объект с методом .
- : необязательный параметр, используемый для определения набора параметров, специфичных для конкретного CSV.
- : необязательный параметр, который можно использовать для переопределения существующих параметров форматирования.
Добавление в запрос новых файлов и обновление сводной таблицы
Через два месяца в наше распоряжение поступило еще два файла с данными за апрель и май. Их также требуется добавить в сводную таблицу.
И вот здесь наступает момент истины. Все что нужно, это закинуть новые файлы в указанную папку и на ленте во вкладке Данные нажать Обновить все. Первое нажатие обновит все запросы, второе – сводные таблицы.
Power Query вновь обратился в папку по указанному адресу, затащил к себе все файлы, раскрыл их, повторил все шаги обработки и выгрузил в Excel. Второе нажатие кнопки обновило сводную таблицу.
Следует только помнить, что для объединения подобным образом таблиц из разных текстовых файлов необходимо полное совпадение заголовков, иначе они автоматически разведутся по разным столбцам.
Серия видеоуроков о Power Query.
Диалекты и параметры форматирования¶
Для упрощения задания формата входных и выходных записей, конкретные параметры
форматирования группируются в диалекты. Диалект — это подкласс
класса, имеющий набор специфических методов и единственный
метод. Создавая объекты или , программист может
определить строку или подкласс класса как параметр
диалекта. В дополнение, или вместо, параметра dialect, программист может
также определить отдельные параметры форматирования, у которых есть те же имена
как атрибуты, определенный ниже для класса .
Диалекты поддерживают следующие атрибуты:
-
Односимвольная строка, используемая для отделения полей. По
умолчанию .
-
Управляет тем, как сущности quotechar, появляющиеся внутри поля, должены
самостоятельно закавычиваться. Когда , символ удваивается. Когда
, escapechar — используется как префикс к quotechar. По
умолчанию он .При выводе, если doublequote и не установлен escapechar,
поднимается , если quotechar найден в поле.
-
Односимвольная строка используемая writer, чтобы экранировать delimiter,
если quoting установлен в и quotechar, если doublequote —
. При чтении escapechar удаляет какое-либо особое значение со
следующего символа. По умолчанию используется значение , которое
отключает экранирование.
-
Используемая строка используемая для завершения строки, произведенная . По
умолчанию используется значение .Примечание
В жёсто закодированы опознавательные символы или
как конец строки и игнорирует lineterminator. Это поведение может измениться в
будущем.
-
Одиносимвольная строка используемая для заковычивания полей, содержащих
специальные символы, такие как delimiter или quotechar, или которые содержат
символы новой строки. По умолчанию используется значение .
-
Контролирует, когда кавычки должны генерироваться writer и распознаваться
reader. Он может принимать любые константы (см. раздел
) и по умолчанию имеет значение .
-
При , пробелы непосредственно следующие за delimiter, игнорируются.
Значение по умолчанию — .
Как структурированы csv файлы
Шаблоны CSV или файлы данных можно загрузить по ссылкам в верхней части инструмента «Загрузить данные». Первая строка шаблона или файла данных содержит заголовки столбцов. Каждая последующая строка соответствует записи в базе данных. Когда загружается шаблон CSV, он содержит только заголовки столбцов. Поскольку шаблоны используются для добавления новых записей, новые строки будут добавляться для каждой записи.
Когда документ данных CSV загружается, первая строка содержит заголовок столбца, а последующие строки содержат записи данных, которые уже существуют в базе данных. Записи в этих строках можно редактировать или удалять.
В документе CSV каждая строка содержит упорядоченную последовательность заголовков столбцов или значений, разделенных запятыми. Запятые используются для сохранения файловой структуры. Каждая запятая в первой строке (которая содержит заголовки столбцов) разделяет заголовок столбца и место в упорядоченной последовательности столбцов.
Запятые в последующих строках также поддерживают последовательность упорядоченных столбцов, поэтому первое значение в каждой последующей строке представляет значение в первом столбце, второе значение в каждой последующей строке представляет значение во втором столбце и так далее. В отличие от стандартной пунктуации предложений, после запятой не ставится пробел.
Большинство значений заключено в двойные кавычки. Исключением является односимвольное значение, например 1 или 0 (ноль). Заключение значения в двойные кавычки позволяет использовать в поле сложные значения, например, содержащие запятые, без нарушения структуры документа. Например, поле, содержащее ряд элементов, например избранные цвета, может иметь такое значение:
“красный, зеленый и синий”
Вы не будете знать об этих цитатах при просмотре файла данных в приложении для работы с электронными таблицами, но они появляются, когда file просматривается в текстовом редакторе.
С чего начать
Начать нужно с чтения документации.
Что такое CSV-файл?
Это текстовый файл, в котором содержится информация, а поля разделяются специальными символами — разделителями. Поэтому и он называется Comma Separated Values — значения, разделённые запятыми.
В США эти файлы разделяются действительно запятыми, в странах СНГ основным разделителем является точка с запятой, то есть ;
Описание формата CSV-файла и полей читайте в разделе Формат CSV-файла
Создание и изменение CSV-файлов.
Первое что нужно сделать, это установить офисный пакет Apache OpenOffice ( с сайта разработчика)
Не рекомендуется использовать Microsoft Excel. Во-первых, Вы гарантированно получите проблемы с кодировкой файла, во-вторых, Вы не сможете правильно настроить разделители для CSV-файла.
Для того, что бы создать CSV-файл, нужно открыть программу OpenOffice Calc, заполнить Лист1 данными в соответствии с форматом CSV-файла.
Сохранить файл Файл — Сохранить как — Выбрать тип файла «Текст CSV (.csv)». В окне выбрать кодировку Юникод (UTF-8), Разделитель поля точка с запятой ;, Разделитель текста двойная кавычка («).
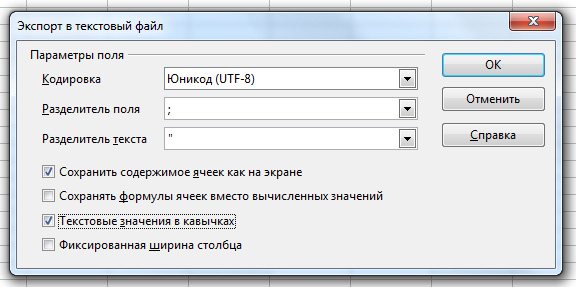
Для открытия CSV-файла выберите Файл — Открыть Ваш файл .csv, в появившемся окне «Импорт текста» : Кодировка: Юникод (UTF-8) Параметры разделителя: Разделитель — Точка с запятой, Разделитель текста — Двойная кавычка («) Другие параметры: Поля в кавычках как текст
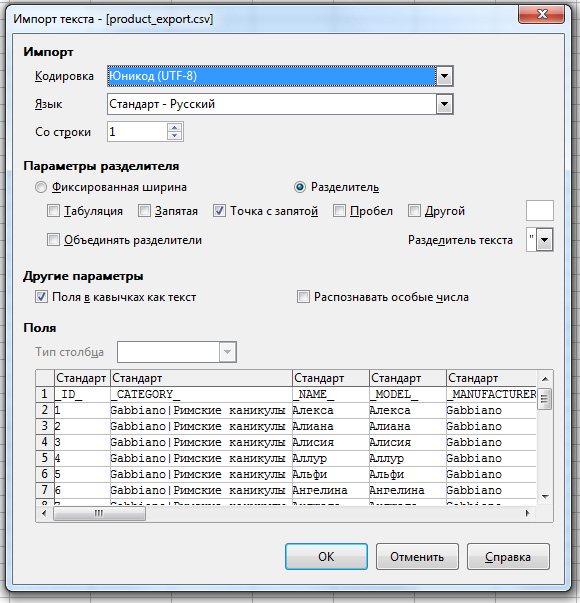
Чтобы правильно открыть в OpenOffice файл .xls, созданный в программе Microsoft Excel, необходимо, что бы файл был сохранён как Excel 97-2003 (*.xls). Далее Вы сможете редактировать его и сохранить как CSV-файл.
Ваш первый CSV-файл
Для того, что бы посмотреть как выглядит CSV-файл, и как нужно его заполнять, сделайте первый экспорт из Вашего магазина:
Зайдите в Товары — Экспорт, выберите справа необходимые поля для экспорта;
Выберите категорию и производителя (можно опустить) или воспользуйтесь фильтром Включить фильтр товаров;
Установите Лимит экспорта: 0-2 (два товара, начиная с первого, или на Ваш выбор);
Если нужны категории товара то обратите внимание на опции Экспорт категорий: , Экспорт только главной категории: , Разделитель для категорий;
Нажмите Экспорт;
Важно: перед тем как сделать первый импорт товара из CSV-файла, нужно зайти в Товары — Настройки, установить соответствующие настройки, сохранить, и после этого можно приступать к импорту. Описание опций экспорта товаров читайте в разделе Экспорт товаров
Чтение¶
Пример чтения файла в формате CSV (файл csv_read.py):
import csv
with open('sw_data.csv') as f
reader = csv.reader(f)
for row in reader
print(row)
Вывод будет таким:
$ python csv_read.py
В первом списке находятся названия столбцов, а в остальных
соответствующие значения.
Обратите внимание, что сам csv.reader возвращает итератор:
In 1]: import csv
In 2]: with open('sw_data.csv') as f
... reader = csv.reader(f)
... print(reader)
...
<_csv.reader object at 0x10385b050>
При необходимости его можно превратить в список таким образом:
In 3]: with open('sw_data.csv') as f
... reader = csv.reader(f)
... print(list(reader))
...
, 'sw1', 'Cisco', '3750', 'London'], 'sw2', 'Cisco', '3850', 'Liverpool'], 'sw3', 'Cisco', '3650', 'Liverpool'], 'sw4', 'Cisco', '3650', 'London']]
Чаще всего заголовки столбцов удобней получить отдельным объектом. Это
можно сделать таким образом (файл csv_read_headers.py):
import csv
with open('sw_data.csv') as f
reader = csv.reader(f)
headers = next(reader)
print('Headers: ', headers)
for row in reader
print(row)
Иногда в результате обработки гораздо удобней получить словари, в
которых ключи — это названия столбцов, а значения — значения столбцов.
Для этого в модуле есть DictReader (файл csv_read_dict.py):
import csv
with open('sw_data.csv') as f
reader = csv.DictReader(f)
for row in reader
print(row)
print(row'hostname'], row'model'])
Вывод будет таким:
$ python csv_read_dict.py
{'hostname': 'sw1', 'vendor': 'Cisco', 'model': '3750', 'location': 'London, Globe Str 1 '}
sw1 3750
{'hostname': 'sw2', 'vendor': 'Cisco', 'model': '3850', 'location': 'Liverpool'}
sw2 3850
{'hostname': 'sw3', 'vendor': 'Cisco', 'model': '3650', 'location': 'Liverpool'}
sw3 3650
{'hostname': 'sw4', 'vendor': 'Cisco', 'model': '3650', 'location': 'London, Grobe Str 1'}
sw4 3650
Важная информация о редактировании файлов csv
Вся система выходит из строя, если в строке стоит пропущенная или лишняя запятая. Каждое значение после этого отсутствующего или лишнего поля данных будет введено в неправильный столбец
В худшем случае база данных может быть повреждена настолько серьезно, что потребуется вернуться к версии резервной копии, что приведет к потере самых последних изменений данных и проблем для администратора, поэтому важно поддерживать файловую структуру. Столбцы в вашем CSV-файле могут появляться в любом порядке, если эта последовательность сохраняется
Другими словами, порядок, в котором заголовки столбцов появляются в первой строке, должен повторяться в последующих строках данных, чтобы данные в каждом поле можно было сопоставить с правильным столбцом. У вас есть возможность опустить любые столбцы, в которых не хотите добавлять или редактировать данные, если только этот столбец не требуется для инструмента загрузки данных, базы данных или правил конфигурации сайта. На самом деле рекомендуется опускать ненужные столбцы, чтобы упростить структуру файла данных и снизить вероятность появления ошибок в ненужном столбце. Нельзя пропустить поля, необходимые для инструмента «Загрузить данные», но можно опустить поля, необходимые для базы данных, при условии, что значение по умолчанию подходит для всех записей, которые вы добавляете или редактируете. Если значение по умолчанию не подходит ни для одной из записей в вашем файле данных, необходимо включить этот столбец и указать соответствующие значения для этих записей. Поля назначения в базе данных хранят различные версии значений, представленных на веб-страницах. Например, пользовательская цель «Представитель компании» хранится в базе данных как «company_rep». Значения сопоставляются друг с другом и преобразуются по мере загрузки и выгрузки данных из базы данных. Возможно, будет проще использовать значение базы данных, которое можно увидеть, при загрузке файла данных CSV по ссылкам в верхней части файла данных для загрузки.
Онлайн конвертер CSV
Благодаря этому пункту обе таблицы будут связаны, так что изменения в исходной таблице будут автоматически отображаться в Access. Внесение изменений в таблицу Access не будут влиять на данные исходной таблице.
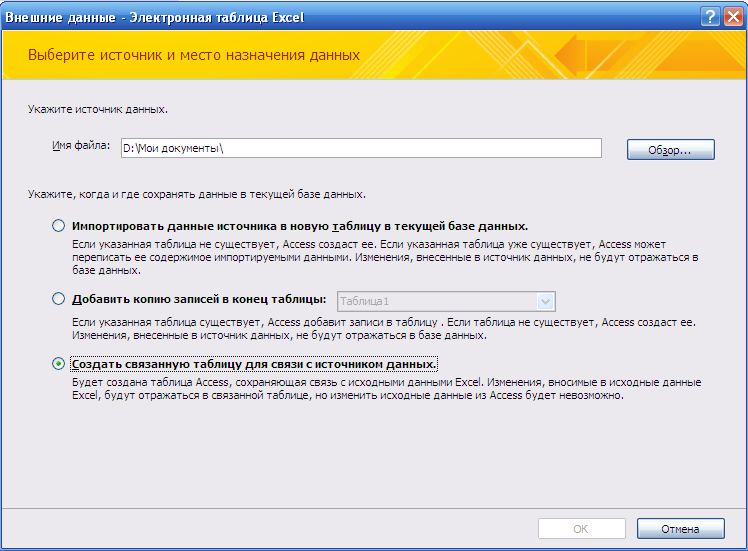
Нажмите ОК. И у вас откроется второе диалоговое окно — Связь с электронной таблицей.
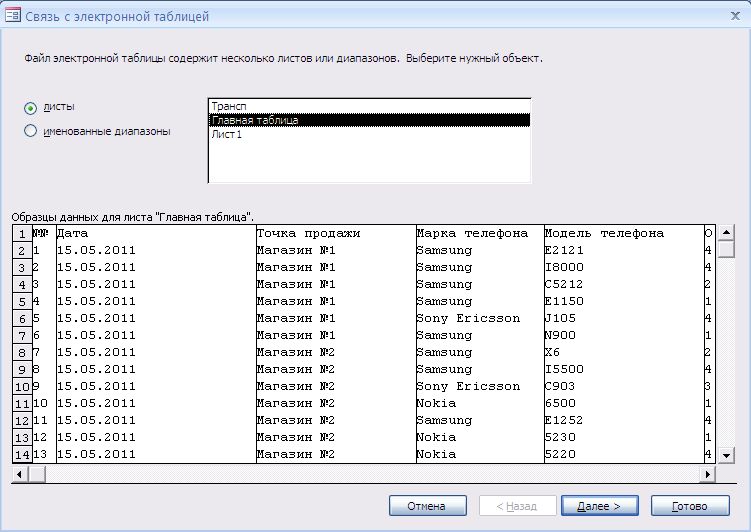
Здесь вы можете выбрать лист, который содержит необходимую таблицу или имя диапазона, если всей таблице оно присвоено. Нажимаем кнопку Далее.
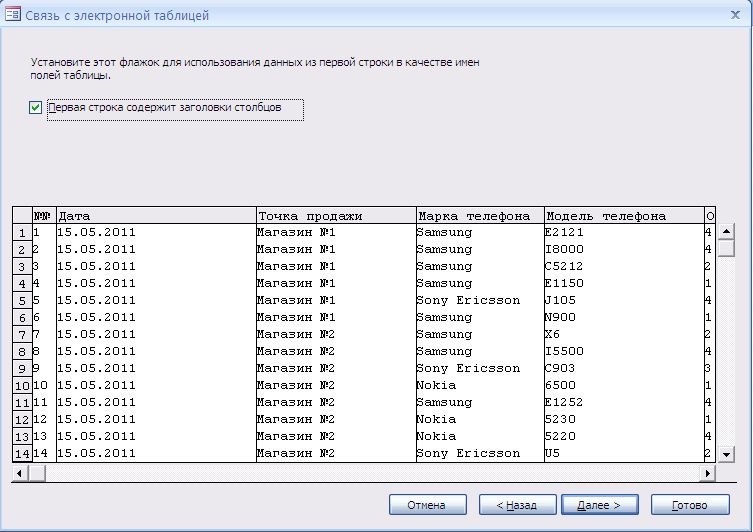
Здесь необходимо указать, содержит ли первая строчка названия столбцов.
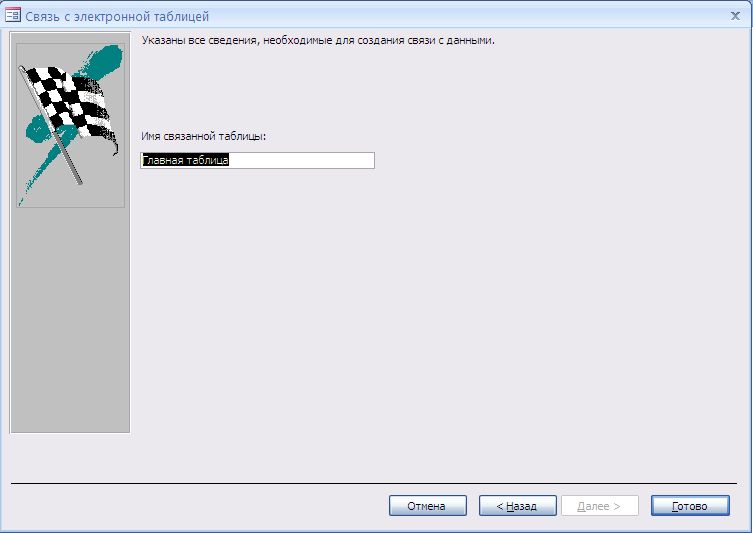
На последнем шаге вам предложат указать Имя связанной таблицы. Нажимаем Готово.
После этого Access предупредит о завершении связывания таблиц — экспорт из Excel’a/импорт в Access завершен.
В начало страницы
Как преобразовать файл Excel в CSV
Если требуется экспортировать файл Excel в какое-либо другое приложение, например, в адресную книгу Outlook или в базу данных Access, предварительно преобразуйте лист Excel в файл CSV, а затем импортируйте файл .csv в другое приложение. Ниже дано пошаговое руководство, как экспортировать рабочую книгу Excel в формат CSV при помощи инструмента Excel – «Сохранить как».
- В рабочей книге Excel откройте вкладку Файл (File) и нажмите Сохранить как (Save as). Кроме этого, диалоговое окно Сохранение документа (Save as) можно открыть, нажав клавишу F12.
- В поле Тип файла (Save as type) выберите CSV (разделители – запятые) (CSV (Comma delimited)).Кроме CSV (разделители – запятые), доступны несколько других вариантов формата CSV:
- CSV (разделители – запятые) (CSV (Comma delimited)). Этот формат хранит данные Excel, как текстовый файл с разделителями запятыми, и может быть использован в другом приложении Windows и в другой версии операционной системы Windows.
- CSV (Macintosh). Этот формат сохраняет книгу Excel, как файл с разделителями запятыми для использования в операционной системе Mac.
- CSV (MS-DOS). Сохраняет книгу Excel, как файл с разделителями запятыми для использования в операционной системе MS-DOS.
- Текст Юникод (Unicode Text (*txt)). Этот стандарт поддерживается почти во всех существующих операционных системах, в том числе в Windows, Macintosh, Linux и Solaris Unix. Он поддерживает символы почти всех современных и даже некоторых древних языков. Поэтому, если книга Excel содержит данные на иностранных языках, то рекомендую сначала сохранить её в формате Текст Юникод (Unicode Text (*txt)), а затем преобразовать в CSV, как описано далее в разделе .
Замечание: Все упомянутые форматы сохраняют только активный лист Excel.
- Выберите папку для сохранения файла в формате CSV и нажмите Сохранить (Save).После нажатия Сохранить (Save) появятся два диалоговых окна. Не переживайте, эти сообщения не говорят об ошибке, так и должно быть.
- Первое диалоговое окно напоминает о том, что В файле выбранного типа может быть сохранён только текущий лист (The selected file type does not support workbooks that contain multiple sheets). Чтобы сохранить только текущий лист, достаточно нажать ОК.Если нужно сохранить все листы книги, то нажмите Отмена (Cancel) и сохраните все листы книги по-отдельности с соответствующими именами файлов, или можете выбрать для сохранения другой тип файла, поддерживающий несколько страниц.
- После нажатия ОК в первом диалоговом окне, появится второе, предупреждающее о том, что некоторые возможности станут недоступны, так как не поддерживаются форматом CSV. Так и должно быть, поэтому просто жмите Да (Yes).
Вот так рабочий лист Excel можно сохранить как файл CSV. Быстро и просто, и вряд ли тут могут возникнуть какие-либо трудности.
Чтение файла CSV
Давайте посмотрим, как читать CSV-файл, используя вспомогательные модули, которые мы обсуждали выше.
Создайте свой CSV-файл и сохраните его как example.csv. Убедитесь, что он имеет расширение и заполните некоторые данные. Здесь у нас есть CSV-файл, который содержит имена учеников и их оценки.
Ниже приведен код для чтения данных в нашем CSV с использованием функции и класса .
Чтение CSV-файла с помощью csv.reader
В приведенном выше коде мы импортируем модуль CSV, а затем открываем наш файл CSV в виде . Затем мы определяем объект reader и используем метод для извлечения данных в объект. Затем мы перебираем объект и извлекаем каждую строку наших данных.
Мы показываем прочитанные данные, печатая их содержимое на консоль. Мы также указали обязательные параметры, такие как разделитель, кавычка и цитирование.
Вывод
Чтение CSV-файла с помощью DictReader
Как мы упоминали выше, DictWriter позволяет нам читать CSV-файл, отображая данные в словарь вместо строк, как в случае с модулем
Хотя имя поля является необязательным параметром, важно всегда помечать столбцы для удобства чтения
Вот как читать CSV, используя класс DictWriter.
Сначала мы импортируем модуль csv и инициализируем пустой список , который мы будем использовать для хранения полученных данных. Затем мы определяем объект reader и используем метод для извлечения данных в объект. Затем мы перебираем объект и извлекаем каждую строку наших данных.
Наконец, мы добавляем каждую строку в список результатов и выводим содержимое на консоль.
Вывод
Как вы можете видеть выше, лучше использовать класс DictReader, потому что он выдает наши данные в формате словаря, с которым легче работать.
Импорт данных из файлов с разделителями-запятыми
Элементы конфигурации, содержащиеся в файле значений с разделителями-запятыми (.csv), могут быть импортированы в базу данных Service Manager с помощью функции импорта из CSV-файла. Эта функция позволяет выполнять массовый импорт экземпляров любого типа класса или проекции, определенного в базе данных Service Manager. Эта функция может использоваться для следующих операций.
-
Создание экземпляров элемента конфигурации или рабочего элемента из данных, хранящихся в табличном формате.
-
Массовое изменение существующих экземпляров базы данных.
-
Заполнение Service Manager базы данных с помощью данных, экспортированных из внешней базы данных.
-
Сокращение объема данных, вводимых в формы при одновременном создании большого количества экземпляров класса.
Примечание
Импорт множества сложных элементов (например, 5 000 проекций компьютеров) может занять час или более. В течение этого времени Service Manager продолжит функционировать.
Для импорта набора экземпляров с помощью функции «Импорт из CSV-файла» требуются два файла.
-
Файл данных, состоящий из последовательности экземпляров объектов, разделенных запятыми. Файл данных должен иметь расширение CSV.
-
Файл форматирования, который указывает тип класса или тип проекции для экземпляров, присутствующих в файле данных. Каждый экземпляр в файле данных относится к этому виду. В файле форматирования также указывается (1) подмножество свойств, а для проекций указываются компоненты. Они импортируются для указанного типа. Кроме того, указывается (2) порядок, в котором эти свойства следуют в виде столбцов в связанном в файле данных. Файл форматирования должен иметь расширение XML, а его имя должно совпадать с именем CSV-файла, который описывает файл форматирования.








