Python regex: re.match(), re.search(), re.findall() with example
Содержание:
Введение в ФП
Говоря о ФП сразу следует подчеркнуть, что программирование через функции далеко не всегда ФП, чаще всего это всего лишь процедурный стиль программирования. Чтобы попробовать понять ФП — необходимо разобраться, что это такое, и помогут нам в этом теоретические знания.
Выделяют две крупные парадигмы программирования: императивная и декларативная.
Императивное программирование предполагает ответ на вопрос “Как?”. В рамках этой парадигмы вы задаете последовательность действий, которые нужно выполнить, для того чтобы получить результат. Результат выполнения сохраняется в ячейках памяти, к которым можно обратиться впоследствии.
Декларативное программирование предполагает ответ на вопрос “Что?”. Здесь вы описываете задачу, даете спецификацию, говорите, что вы хотите получить в результате выполнения программы, но не определяете, как этот ответ будет получен. Каждая из этих парадигм включает в себя более специфические модели.
В продуктовой разработке наибольшее распространение получили процедурное и объектно-ориентированное программирование из группы “императивное программирование” и функциональное программирование из группы “декларативное программирование”.
В рамках процедурного подхода к программированию основное внимание сосредоточено на декомпозиции – разбиении программы / задачи на отдельные блоки / подзадачи. Разработка ведётся пошагово, методом “сверху вниз”
Наиболее распространенным языком, который предполагает использование процедурного подхода к программирования является язык C, в нем, основными строительными блоками являются функции.
В рамках объектно-ориентированного (ООП) подхода программа представляется в виде совокупности объектов, каждый из которых является экземпляром определенного класса, классы образуют иерархию наследования. ООП базируется на следующих принципах: инкапсуляция, наследование, полиморфизм, абстракция. Примерами языков, которые позволяют вести разработку в этой парадигме являются C#, Java.
В рамках функционального программирования выполнение программы – процесс вычисления, который трактуется как вычисление значений функций в математическом понимании последних (в отличие от функций как подпрограмм в процедурном программировании). Языки, которые реализуют эту парадигму – Haskell, Lisp.
Языки, которые можно отнести в функциональной парадигме обладают определенным набором свойств. Если язык не является чисто функциональным, но реализует эти свойства, то на нем можно разрабатывать, как говорят, в функциональном стиле.
Введение в итераторы
Итерация — по сути является перебором значений. Вот обычный пример, который встречается повсюду.
Также, как мы знаем, итерация может происходить по многим типам объектов (не только спискам). Причина, почему мы можем итерироваться по объектам — реализация специального протокола
Внутри под капотом обычной итерации.
Происходит примерно следующее:
Фактически, любой объект, который поддерживает конструкцию называется итерируемым. Чтобы добавить его поддержку в своём классе, нам необходимо имплементировать методы и .
Например, посмотрим, как имплементировать такое:
Его реализация будет такова:
Разность re.match и re.search
re.match соответствует только начало строки, если начало строки не соответствует регулярному выражению, совпадение не найдено, функция возвращает None, и re.search совпадают со строкой, пока не найдет совпадения.
Пример:
#!/usr/bin/python3
import re
line = "Cats are smarter than dogs";
matchObj = re.match( r'dogs', line, re.M|re.I)
if matchObj:
print ("match --> matchObj.group() : ", matchObj.group())
else:
print ("No match!!")
matchObj = re.search( r'dogs', line, re.M|re.I)
if matchObj:
print ("search --> matchObj.group() : ", matchObj.group())
else:
print ("No match!!")
No match!! search --> matchObj.group() : dogs
Методы регулярных выражений
\w -> Совпадения с буквенно-цифровыми символами \W – > Совпадения с не буквенно-цифровыми символами \d -> Совпадения с цифрами \D -> Совпадения со всеми не цифрами \s- > Совпадения с одним пробелом \S —> Совпадения, за исключением расширения пространства все \t -> Вкладка “Совпадения” \n -> Совпадения новой строки \r -> Возврат совпадений . –> Соответствует любому символу, кроме \n () – > группирует регулярные выражения и возвращает сопоставленный текст a|b -> Соответствует либо a, либо b ^ -> начальная позиция $ -> конечная позиция {m} -> Соответствует и должно соответствовать m {m,} -> Соответствует больше, чем m {m,n} -> Соответствует цифре между m и n по длине ? –> -> Соответствует одному или нулевому вхождению паттерна плюс(+) –> Соответствует одному или нескольким вхождениям паттерна
Совпадения новой строки \r -> Возврат совпадений . –> Соответствует любому символу, кроме \n () – > группирует регулярные выражения и возвращает сопоставленный текст a|b -> Соответствует либо a, либо b ^ -> начальная позиция $ -> конечная позиция {m} -> Соответствует и должно соответствовать m {m,} -> Соответствует больше, чем m {m,n} -> Соответствует цифре между m и n по длине ? –> -> Соответствует одному или нулевому вхождению паттерна плюс(+) –> Соответствует одному или нескольким вхождениям паттерна” />
sub —-> Найдите все подстроки, где re совпадает, и замените их другой строкой subn – – – – > такой же, как sub (), но возвращает новую строку и количество замен start – – – – > Это даст начальную позицию end – – – – > Это даст конечную позицию span – – – – > Это даст начальную и конечную позиции подстроки search – – – – > Поиск всей строки match – – – – > Поиск первого слова findall – – – – > Несколько раз поиск в строке compile – – – – – > Мы можем скомпилировать шаблон в объект pattern
Здесь я показываю, как использовать некоторые из этих методов
Согласуемые символы
Когда вам нужно найти символ в строке, в большей части случаев вы можете просто использовать этот символ или строку. Так что, когда нам нужно проверить наличие слова «dog», то мы будем использовать буквы в dog. Конечно, существуют определенные символы, которые заняты регулярными выражениями. Они так же известны как метасимволы. Внизу изложен полный список метасимволов, которые поддерживают регулярные выражения Python:
Python
. ˆ $ * + ? { } | ( )
| 1 | . ˆ $ * + ? { } | ( ) |
Давайте взглянем как они работают. Основная связка метасимволов, с которой вы будете сталкиваться, это квадратные скобки: . Они используются для создания «класса символов», который является набором символов, которые вы можете сопоставить. Вы можете отсортировать символы индивидуально, например, так: . Это сопоставит любой внесенный в скобки символ. Вы также можете использовать тире для выражения ряда символов, соответственно: . В этом примере мы сопоставим одну из букв в ряде между a и g. Фактически для выполнения поиска нам нужно добавить начальный искомый символ и конечный. Чтобы упростить это, мы можем использовать звездочку. Вместо сопоставления *, данный символ указывает регулярному выражению, что предыдущий символ может быть сопоставлен 0 или более раз. Давайте посмотрим на пример, чтобы лучше понять о чем речь:
Python
‘a*f
| 1 | ‘ab-f*f |
Этот шаблон регулярного выражения показывает, что мы ищем букву а, ноль или несколько букв из нашего класса, и поиск должен закончиться на f. Давайте используем это выражение в Python:
Python
import re
text = ‘abcdfghijk’
parser = re.search(‘a*f’)
print(parser.group()) # ‘abcdf’
|
1 2 3 4 5 |
importre text=’abcdfghijk’ parser=re.search(‘a*f’) print(parser.group())# ‘abcdf’ |
В общем, это выражение просмотрит всю переданную ей строку, в данном случае это abcdfghijk.Выражение найдет нашу букву «а» в начале поиска. Затем, в связи с тем, что она имеет класс символа со звездочкой в конце, выражение прочитает остальную часть строки, что бы посмотреть, сопоставима ли она. Если нет, то выражение будет пропускать по одному символу, пытаясь найти совпадения. Вся магия начинается, когда мы вызываем поисковую функцию модуля re. Если мы не найдем совпадение, тогда мы получим None. В противном случае, мы получим объект Match. Чтобы увидеть, как выглядит совпадение, вам нужно вызывать метод group. Существует еще один повторяемый метасимвол, аналогичный *. Этот символ +, который будет сопоставлять один или более раз. Разница с *, который сопоставляет от нуля до более раз незначительна, на первый взгляд.
Символу + необходимо как минимум одно вхождение искомого символа. Последние два повторяемых метасимвола работают несколько иначе. Рассмотрим знак вопроса «?», применение которого выгладит так: “co-?op”. Он будет сопоставлять и “coop” и “co-op”. Последний повторяемый метасимвол это {a,b}, где а и b являются десятичными целыми числами. Это значит, что должно быть не менее «а» повторений, но и не более «b». Вы можете попробовать что-то на подобии этого:
Python
xb{1,4}z
| 1 | xb{1,4}z |
Это очень примитивный пример, но в нем говорится, что мы сопоставим следующие комбинации: xbz, xbbz, xbbbz и xbbbbz, но не xz, так как он не содержит «b».
Следующий метасимвол это ^. Этот символ позволяет нам сопоставить символы которые не находятся в списке нашего класса. Другими словами, он будет дополнять наш класс. Это сработает только в том случае, если мы разместим ^ внутри нашего класса. Если этот символ находится вне класса, тогда мы попытаемся найти совпадения с данным символом. Наглядным примером будет следующий: . Так, выражения будет искать совпадения с любой буквой, кроме «а». Символ ^ также используется как анкор, который обычно используется для совпадений в начале строки.
Существует соответствующий якорь для конце строки – «$». Мы потратим много времени на введение в различные концепты применения регулярных выражений. В следующих параграфах мы углубимся в более подробные примеры кодов.
Example of w+ and ^ Expression
- «^»: This expression matches the start of a string
- «w+»: This expression matches the alphanumeric character in the string
Here we will see a Python RegEx Example of how we can use w+ and ^ expression in our code. We cover the function re.findall() in Python, later in this tutorial but for a while we simply focus on \w+ and \^ expression.
For example, for our string «guru99, education is fun» if we execute the code with w+ and^, it will give the output «guru99».
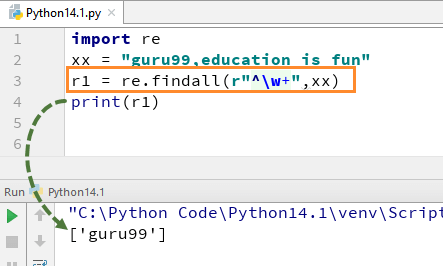
import re xx = "guru99,education is fun" r1 = re.findall(r"^\w+",xx) print(r1)
Remember, if you remove +sign from the w+, the output will change, and it will only give the first character of the first letter, i.e.,
Строительные блоки регулярных выражений
В этом разделе мы рассмотрим элементы, которые составляют Regex и как построен регулярные вещества. REGEX содержит группы, и каждая группа содержит различные спецификаторы, такие как классы символов, повторители, идентификаторы и т. Д. Спецификаторы – это строки, которые соответствуют определенным типам рисунка и имеют свой собственный формат для описания желаемого рисунка. Давайте посмотрим на общие спецификаторы:
Идентификаторы
Идентификатор соответствует подмножеству символов E.g., строчные буквы, числовые цифры, пробел и т. Д. Regex предоставляет список удобных идентификаторов для соответствия различных подмножествах. Некоторые часто используемые идентификаторы:
- цифры (числовые символы) в строке
- что-нибудь, кроме цифра
- Белое пространство (например, пространство, вкладка и т. Д. ,.)
- что-нибудь, кроме пространства
- Письма/алфавиты и цифры
- что-нибудь, кроме письмо
- Любой персонаж, который может отделить слова (например, пространство, дефис, толстой кишки и т. Д. ,.)
- любой символ, кроме новой линии. Следовательно, это называется оператором подстановки. Таким образом, «. *» Будет соответствовать любому персонажу, любому Nuber Times.
Примечание: в приведенном выше примере Regex и все остальные в этом разделе мы опускаем ведущую от строковой буквы Regex для ради читабельности. Любой буквальный приведенный здесь должен быть объявлен сырой строковой буквальной буквами при использовании в коде Python.
Повторители
Репретеритор используется для уточнения одного или нескольких вхождений группы. Ниже приведены некоторые часто используемые ретрансляторы.
`*` Символ
Оператор Звездочки указывает на 0 или более повторений предыдущего элемента, как можно больше. «ab *» будет соответствовать «A», «ab», «ABB» или «A», а затем любое количество B.
`+` Символ
Оператор Plus указывает на 1 или более повторений предыдущего элемента, как можно больше. «AB +» будет соответствовать «A», «ab», «ABB» или «A», а затем 1 вхождение «B»; Это не будет соответствовать «a».
`?` Символ
Этот символ указывает предыдущий элемент с большинством, то есть, он может или не может присутствовать в строке, подходящей. Например, «ab +» будет соответствовать «A» и «AB».
`{N}` кудрявые скобки
Кредиковые брекеты указывают предыдущий элемент, который должен соответствовать ровно N раз. B {4} будет сопоставлять ровно четырех символов «B», но не более/менее 4.
Символы *, + ,? и {} называются ретрансляторами, поскольку они указывают количество раз, когда предыдущий элемент повторяется.
Разные спецификаторы
`[] Квадратные скобки
Квадратные брекеты соответствуют любому одному символу, заключенному внутри него. Например, будет соответствовать любому из строчных гласных гласных, когда будет соответствовать любому символу из A-Z (чувствителен к регистру). Это также называется классом персонажа.
`|` “
Вертикальная полоса используется для разделения альтернатив. Фото | Фото спички либо «фото» или «фото».
`^` Символ
Символ CARET указывает положение для матча, в начале строки, кроме при использовании внутри квадратных скобок. Например, «^ i» будет сочетать строку, начиная с «I», но не сопоставлю строк, которые не имеют «я» в начале. Это, по сути, то же самое, что и функциональность, предоставленные Функция против функция.
При использовании в качестве первого символа внутри класса символов он инвертирует соответствующий набор символов для класса символов. Например, «» будет соответствовать любому символу, отличным от A, E, I, O или U.
Символ `$`
Символ доллара указывает положение для матча, в конце строки.
`()” Скобки
Скобка используется для группировки разных символов Re, действовать как один блок. ( \ D +) будет сопоставить шаблоны, содержащие A-Z, а затем любая цифра. Весь матч рассматривается как группа и может быть извлечена из строки. Больше на это позже.
2 ответа
Лучший ответ
Re.search возвращает либо совпадающий объект, либо None. Сначала вызовите re.search и сохраните его значение в переменной, а затем проверьте, является ли оно None. Просто убедитесь, что вы проверили, если это не None, прежде чем пытаться извлечь значения из него.
Кроме того, вам не нужно использовать , чтобы проверить, равно ли что-либо ничему, просто протестируйте его, как если бы оно было логическим
Наконец, вы, кажется, хотите извлечь данные из регулярного выражения. Если вы хотите сделать это, вы можете вызвать в регулярном выражении, чтобы получить содержимое совпадения (на самом деле это первая группа, но вы читаете больше об этом на странице регулярного выражения, это должно работать для ваших целей). Затем конвертируйте результат во все, что вам нужно. Например, вы можете найти и извлечь первое число в строке и проверить, превышает ли оно какое-либо значение, например, следующее:
Надеюсь это поможет. Загляните в документацию, если хотите узнать больше о регулярных выражениях. Документы: https://docs.python.org/3/library/re.html а>
1
ComedicChimera
30 Сен 2018 в 22:11
Обратите внимание, что мне известно, что мой ответ не является ответом на ваш вопрос, однако я считаю, что все же важно сказать вам следующее. Regex — очень мощный инструмент, у которого есть целевые приложения или проблемы, которые нужно решить. Но ИМО, ваша тема не для регулярных выражений
Но ИМО, ваша тема не для регулярных выражений
Regex — очень мощный инструмент, у которого есть целевые приложения или проблемы, которые нужно решить. Но ИМО, ваша тема не для регулярных выражений.
Существует библиотека для Python, которая может работать с датой и временем. Пожалуйста, подумайте об использовании такого подхода:
Обратите внимание, что основная часть программы связана с двойным улавливанием ошибок ввода пользователя. Но все же я считаю, что это очень удобный способ
И: здесь ваш сложный расчет — это просто вычитание … Таким образом, это приведет к программе с точки зрения пользователя, например:
Просто просмотрите, возможно, вам понравится и вы будете работать в этом направлении самостоятельно. И все же, если вам действительно придется протестировать , потому что это так интересно — для этого будут другие проблемы …
SpghttCd
30 Сен 2018 в 22:37
Особые последовательности
Специальная последовательность — это , за которым следует один из символов в списке ниже, и имеет особое значение:
| Символ | Описание | Пример |
|---|---|---|
| \A | Возвращает совпадение, если указанные символы находятся в начале нить | «\AThe» |
| \b | Возвращает совпадение, в котором указанные символы находятся в начале или в конец слова («r» в начале означает, что строка рассматривается как «необработанная строка») | r»\bain»r»ain\b» |
| \B | Возвращает совпадение, в котором указанные символы присутствуют, но НЕ в начале (или на конец) слова («r» в начале гарантирует, что строка обрабатывается как «необработанная строка») | r»\Bain»r»ain\B» |
| \d | Возвращает совпадение, в котором строка содержит цифры (числа от 0 до 9). | «\d» |
| \D | Возвращает совпадение, в котором строка НЕ содержит цифр. | «\D» |
| \s | Возвращает совпадение, в котором строка содержит символ пробела. | «\s» |
| \S | Возвращает совпадение, в котором строка НЕ содержит пробела. | «\S» |
| \w | Возвращает совпадение, в котором строка содержит любые символы слова (символы из от a до Z, цифры от 0 до 9 и символ подчеркивания _) | «\w» |
| \W | Возвращает совпадение, в котором строка НЕ содержит символов слова | «\W» |
| \Z | Возвращает совпадение, если указанные символы находятся в конце строки | «Spain\Z» |
Вопросы пользователей по теме Python
Класс Python islice не работает должным образом
Я пишу функцию, которая делит список на (почти) равные n распределений. Я хочу, чтобы эта функция возвращала генератор, но, похоже, возникла проблема с получением генератора. Функция отлично работает с итерациями. Взгляните на этот фрагмент:
import itertools
def divide_list(array, n, gen_length….
10 Авг 2021 в 05:23
Как округлить значение, выводимое моей функцией?
Я пишу код, который переводит узлы в км / ч.
def to_kmh(knots):
# Calculate the speed in km/h
return 1.852 * knots
# Write the rest of your program here
knots = float(input(‘Speed (kn): ‘))
if to_kmh(knots) <60:
print(f'{to_kmh(knots)} — Go faster!’)
elif to_kmh(knots) <100:
print(f'{to_km….
10 Авг 2021 в 03:13
Вставка строки по умолчанию, если в словаре нет значения
Я просматриваю список словарей и очищаю текст, чтобы избавиться от тегов <h2>, запятых и т. Д., Чтобы при помещении значений в фрейм данных pandas они просто отображали текст:
Вот функция на данный момент:
def first_clean(my_dict):
my_dict = {k: v for k, v in my_dict.items()}
for k, v in ….
10 Авг 2021 в 01:04
неожиданный результат с выражением присваивания
Я написал этот код, чтобы попробовать выражение присваивания:
foods= list()
while food := input(«your food?:») != «q»:
foods.append(food)
else:
print(foods)
Но после ввода сучи и риса после бега результат был
На самом деле такого результата не ожидал. Вы можете объяснить??….
10 Авг 2021 в 00:04
Почему при использовании ** kwargs появляется ключ kwargs?
Почему появляется {‘kwargs’:{‘1′:’a’, ‘2’:’b’}}, когда я запускаю test_func()? Я ожидал, что напечатает только это: {‘1′:’a’, ‘2’:’b’}.
Код:
class MyClass:
def __init__(self, **kwargs):
self.kwargs = kwargs
def test_func(self):
print(self.kwargs)
test_kwargs = {‘1′:’a’, ‘2….
9 Авг 2021 в 23:48
Печать всех элементов списка рядом с другой строкой
Я знаю, что о печати всех элементов строки много раз спрашивали и отвечали, но у меня возникли проблемы с поиском решения для выполнения этого в строке и рядом с другим оператором.
У меня следующая установка:
api_endpoints =
print(*api_endpoints, sep=’, ‘)
# candidate, emp….
9 Авг 2021 в 22:56
Объединить последовательные и перекрывающиеся диапазоны дат
Я надеюсь, что кто-нибудь здесь может мне помочь. Я перепробовал практически каждый поиск в Интернете, который только мог придумать, но не могу найти информацию, которая поможет мне получить то, что я ищу.
У меня есть несколько наборов данных, в которых периоды обслуживания клиентов являются послед….
9 Авг 2021 в 18:43
Обновление Pandas DataFrame и суммирование путем сопоставления индекса с несколькими столбцами из другой серии Pandas
У меня есть
df =
B TF C N
0 356 True 714 1
1 357 True 718 2
2 358 True 722 3
3 359 True 726 4
4 360 False 730 5
lt =
B C
356 714 223
360 730 101
400 800 200
Name: N, dtype: int64
type(lt) => pandas.core.series.Series
Мне нравится рассма….
9 Авг 2021 в 15:55
Разбиение набора данных на части и автоматическое вычисление средних значений этих фрагментов
Мне нужно создать небольшие фрагменты из набора данных. Затем вычислите среднее значение каждого фрагмента. Наконец, создайте список или массив для хранения всех этих средств. Моя цель — автоматизировать процесс. Например: мои данные . Если размер блока равен 3, ….
9 Авг 2021 в 01:20
Я получил пустые значения при преобразовании объекта в int с помощью pandas
Я пытаюсь преобразовать список столбцов из объекта str в целое число с помощью этого метода
df = pd.to_numeric(df, errors=’coerce’)
df = df.apply(np.int64)
NB: тип столбца A — объект
Но у меня такая ошибка ValueError: cannot convert float NaN to integer
Думаю, проблема в том, чт….
8 Авг 2021 в 20:44
Matching Versus Searching
Python offers two different primitive operations based on regular expressions: match checks for a match only at the beginning of the string, while search checks for a match anywhere in the string (this is what Perl does by default).
Example
#!/usr/bin/python import re line = "Cats are smarter than dogs"; matchObj = re.match( r'dogs', line, re.M|re.I) if matchObj: print "match --> matchObj.group() : ", matchObj.group() else: print "No match!!" searchObj = re.search( r'dogs', line, re.M|re.I) if searchObj: print "search --> searchObj.group() : ", searchObj.group() else: print "Nothing found!!"
When the above code is executed, it produces the following result −
No match!! search --> searchObj.group() : dogs
А теперь вернёмся к тем особенностям, которые были изложены в начале статьи
1. Использование генератора дважды
В данном примере, список будет содержать элементы только в первом случае, потому что генераторное выражение — это итератор, а итераторы, как мы уже знаем — сущности одноразовые. И при повторном использовании не будут отдавать никаких элементов.
2. Проверка вхождения элемента в генератор
А теперь дважды проверим, входит ли элемент в последовательность:
В данном примере, элемент будет входить в последовательность только 1 раз, по причине того, что проверка на вхождение проверяется путем перебора всех элементов последовательности последовательно, и как только элемент обнаружен, поиск прекращается. Для наглядности приведу пример:
Как мы видим, при создании списка из генераторного выражения, в нём оказываются все элементы, после искомого. При повторном же создании, вполне ожидаемо, список оказывается пуст.
3. Распаковка словаря
При использовании в цикле , словарь будет отдавать ключи:
Так как распаковка опирается на тот же протокол итератора, то и в переменных оказываются именно ключи:
Шаблон регулярного выражения
Строка шаблона, используя специальный синтаксис для обозначения регулярное выражение:
Буквы и цифры сами. Регулярное выражение при букв и цифр совпадают ту же строку.
Большинство из букв и цифр будет иметь различное значение, когда ему предшествует обратный слэш.
Пунктуация спасшемся только тогда, когда сам матч, или они представляют собой особый смысл.
Сам Backslash должен использовать побег символ обратной косой.
Поскольку регулярные выражения обычно содержат символы, так что вам лучше использовать исходную строку, чтобы представлять их. Элементы схемы (например, г ‘/ т’, что эквивалентно ‘// Т’) совпадает с соответствующим специальные символы.
В следующей таблице перечислены синтаксис регулярных выражений шаблон конкретных элементов. Если ваши модели использования, обеспечивая при этом необязательные флаги аргумент, значение некоторых элементов рисунка будет меняться.
| режим | описание |
|---|---|
| ^ | Соответствует началу строки |
| $ | Соответствует концу строки. |
| , | Соответствует любому символу, кроме символа новой строки, если указан флаг re.DOTALL, вы можете соответствовать любому символу, включая символ новой строки. |
| Он используется для представления группы символов, перечисленных отдельно: матч ‘а’, ‘т’ или ‘K’ | |
| Не [] символов: соответствует в дополнение к а, Ь, с символами. | |
| Re * | 0 или более выражениям. |
| Re + | Один или более совпадающих выражений. |
| повторно? | Матч 0 или 1 по предшествующих регулярных выражений для определения сегментов, не жадный путь |
| Re {п} | |
| повторно {п,} | Точное соответствие п предыдущего выражения. |
| Re {п, т} | Матч п в т раз по предшествующих регулярных выражений для определения сегментов, жадный путь |
| а | б | Совпадение или б |
| (Re) | Выражение матч G в скобках, также представляет собой группу |
| (? Imx) | Регулярное выражение состоит из трех дополнительных флагов: я, м, или х. Она влияет только на область в скобках. |
| (? -imx) | Регулярные выражения Закрыть я, м, или х необязательный флаг. Она влияет только на область в скобках. |
| (?: Re) | Аналогично (…), но не представляет собой группу, |
| (Imx 😕 Re) | Я использую в круглые скобки, м или х необязательный флаг |
| (-imx 😕 Re) | Не используйте I, M в круглых скобках, или х дополнительный флаг |
| (? # …) | Примечание. |
| (? = Re) | Форвард уверен разделитель. Если содержится регулярное выражение, представленное здесь …, успешно матчи в текущем местоположении, и не иначе. Тем не менее, как только содержала выражение была опробована, согласующий двигатель не продвигается, остальная часть узора даже попробовать разделителем правильно. |
| (?! Re) | Нападающий отрицанием разделителем. И, конечно, противоречит разделителем, успешным, когда содержащийся выражение не совпадает с текущей позиции в строке |
| (?> Re) | Независимый поиск по шаблону, устраняя откаты. |
| \ W | Матч алфавитно-цифровой и нижнее подчеркивание |
| \ W | Матч не буквенно-цифровых и подчеркивания |
| \ S | Соответствует любой символ пробела, что эквивалентно . |
| \ S | Соответствует любой непустой символ |
| \ D | Соответствует любому количеству, которое эквивалентно . |
| \ D | Соответствует любому нечисловая |
| \ A | Соответствует началу строки |
| \ Z | Матч конец строки, если она существует символ новой строки, только до конца строки, чтобы соответствовать новой строки. с |
| \ Z | конец строки Match |
| \ G | Матч Матч завершен последнюю позицию. |
| \ B | Матчи границы слова, то есть, оно относится к месту и пробелы между словами. Например, ‘эр \ Ъ’ не может сравниться с «никогда» в «эр», но не может сравниться с «глаголом» в «эр». |
| \ B | Матч граница слова. ‘Er \ B’ может соответствовать «глагол» в «эр», но не может сравниться с «никогда» в «эр». |
| \ N, \ т, и тому подобное. | Соответствует новой строки. Соответствует символу табуляции. подождите |
| \ 1 … \ 9 | Соответствующие подвыражения п-го пакета. |
| \ 10 | Матч первые п пакетов подвыражению, если он после матча. В противном случае, выражение относится к восьмеричный код. |
Feedback¶
Regular expressions are a complicated topic. Did this document help you
understand them? Were there parts that were unclear, or Problems you
encountered that weren’t covered here? If so, please send suggestions for
improvements to the author.
The most complete book on regular expressions is almost certainly Jeffrey
Friedl’s Mastering Regular Expressions, published by O’Reilly. Unfortunately,
it exclusively concentrates on Perl and Java’s flavours of regular expressions,
and doesn’t contain any Python material at all, so it won’t be useful as a
reference for programming in Python. (The first edition covered Python’s
now-removed module, which won’t help you much.) Consider checking
it out from your library.
Выводы
Плюсы:
- Генераторы — невероятно полезный инструмент для решения многообразных проблем
- Сила исходит от способности настраивать пайплайны
- Можно создавать компоненты, которые можно переиспользовать в разных пайплайнах
- Небольшие компоненты, которые просто обрабатывают поток данных
- Намного проще, чем это может быть сделано с помощью ООП шаблонов
- Можно расширить идею пайплайнов во многих направлениях (сеть, потоки, корутины)
Минусы
Использование этого стиля программирования у непосвященных может привести к взрыву головы
Обработка ошибок сложна, потому что у нас много компонентов, связанных вместе
Необходимо уделять особое внимание отладке, надежности и другим вопросам.








