Выбираем базу данных
Содержание:
Типы схемы базы данных
Существует два основных типа схемы базы данных, которые определяют разные части схемы: логическую и физическую.
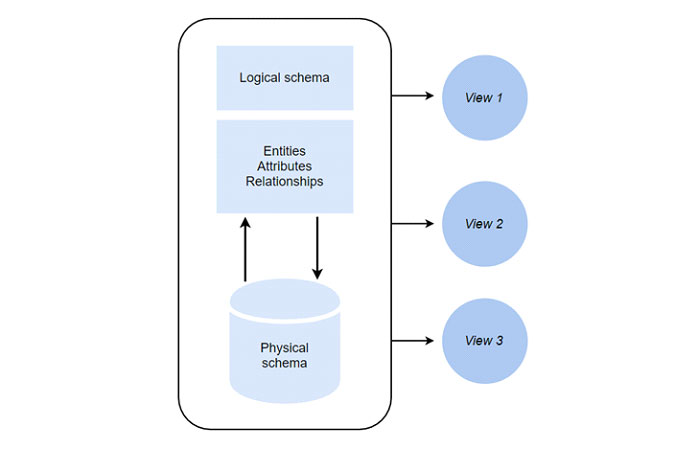
Логический
Схема логической базы данных представляет, как данные организованы в виде таблиц. Он также объясняет, как атрибуты из таблиц связаны друг с другом. В разных схемах используется разный синтаксис для определения логической архитектуры и ограничений.
Чтобы создать логическую схему базы данных, мы используем инструменты для иллюстрации отношений между компонентами ваших данных. Это называется моделированием сущности-отношения (моделирование ER). Он определяет отношения между типами сущностей.
Схема ниже представляет собой очень простую модель ER, которая показывает логический поток в базовом коммерческом приложении. Он объясняет продукт покупателю, который его покупает.
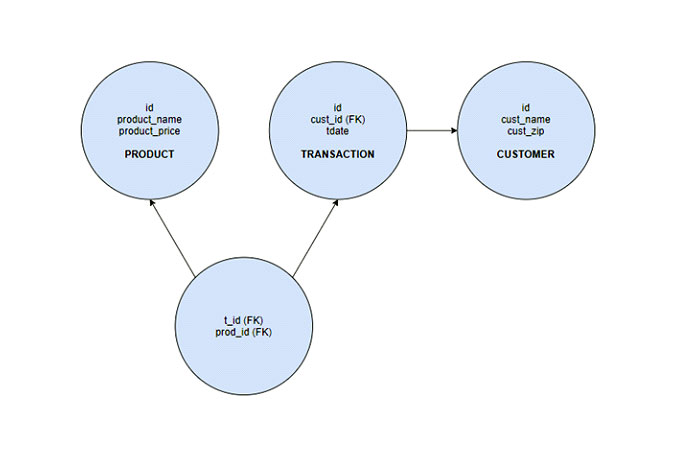
Идентификаторы в каждом из трех верхних кружков указывают первичный ключ объекта. Это идентификатор, который однозначно определяет запись в документе или таблице. FK на схеме — это внешний ключ. Это то, что связывает отношения от одной таблицы к другой.
- Первичный ключ: идентифицировать запись в таблице
- Внешний ключ: первичный ключ для другой таблицы
Модели сущностей-отношений могут быть созданы всевозможными способами, и существуют онлайн-инструменты, которые помогают в построении диаграмм, таблиц и даже SQL для создания вашей базы данных из существующей модели ER. Это поможет создать физическое представление схемы вашей базы данных.
Физический
Схема физической базы данных представляет, как данные хранятся на диске. Другими словами, это реальный код, который будет использоваться для создания структуры вашей базы данных. Например, в MongoDB с мангустом это примет форму модели мангуста. В MySQL вы будете использовать SQL для создания базы данных с таблицами.
По сравнению с логической схемой она включает имена таблиц базы данных, имена столбцов и типы данных.
Теперь, когда мы знакомы с основами схемы базы данных, давайте рассмотрим несколько примеров. Мы рассмотрим наиболее распространенные примеры, с которыми вы можете столкнуться.
Бинарные связи
Бинарные связи – это связи, в которые вступают ровно две сущности. Важнейшее свойство связи – кардинальное число.
Типы бинарных связей:
- Связь типа «один-к-одному» означает, что один экземпляр первой сущности связан не более чем с одним экземпляром второй сущности и, наоборот, один экземпляр второй сущности связан не более чем с одним экземпляром первой сущности.
- Связь типа «один-ко-многим» означает, что один экземпляр первой сущности связан с несколькими экземплярами второй сущности, но при этом один экземпляр второй сущности связан не более чем с один экземпляром первой сущности.
- Связь типа «много-ко-многим» означает, что каждый экземпляр первой сущности может быть связан с несколькими экземплярами второй сущности, и каждый экземпляр второй сущности может быть связан с несколькими экземплярами первой сущности. Эта связь должна быть заменена двумя связями типа один-ко-многим путем создания промежуточной сущности.
Нормализация базы данных
После предварительного проектирования базы данных можно применить правила нормализации, чтобы убедиться, что таблицы структурированы правильно.
В то же время не все базы данных необходимо нормализовать. В целом, базы с обработкой транзакций в реальном времени (OLTP), должны быть нормализованы.
Базы данных с интерактивной аналитической обработкой (OLAP), позволяющие проще и быстрее выполнять анализ данных, могут быть более эффективными с определенной степенью денормализации. Основным критерием здесь является скорость вычислений. Каждая форма или уровень нормализации включает правила, связанные с нижними формами.
Первая форма нормализации
Первая форма нормализации (сокращенно 1NF) гласит, что во время логического проектирования базы данных каждая ячейка в таблице может иметь только одно значение, а не список значений. Поэтому таблица, подобная той, которая приведена ниже, не соответствует 1NF:
Возможно, у вас возникнет желание обойти это ограничение, разделив данные на дополнительные столбцы. Но это также противоречит правилам: таблица с группами повторяющихся или тесно связанных атрибутов не соответствует первой форме нормализации. Например, приведенная ниже таблица не соответствует 1NF:
Вместо этого во время физического проектирования базы данных разделите данные на несколько таблиц или записей, пока каждая ячейка не будет содержать только одно значение, и дополнительных столбцов не будет. Такие данные считаются разбитыми до наименьшего полезного размера. В приведенной выше таблице можно создать дополнительную таблицу «Реквизиты продаж», которая будет соответствовать конкретным продуктам с продажами. «Продажи» будут иметь связь 1:M с «Реквизитами продаж».
Вторая форма нормализации
Вторая форма нормализации (2NF) предусматривает, что каждый из атрибутов должен полностью зависеть от первичного ключа. Каждый атрибут должен напрямую зависеть от всего первичного ключа, а не косвенно через другой атрибут.
Например, атрибут «возраст» зависит от «дня рождения», который, в свою очередь, зависит от «ID студента», имеет частичную функциональную зависимость. Таблица, содержащая эти атрибуты, не будет соответствовать второй форме нормализации.
Кроме этого таблица с первичным ключом, состоящим из нескольких полей, нарушает вторую форму нормализации, если одно или несколько полей не зависят от каждой части ключа.
Таким образом, таблица с этими полями не будет соответствовать второй форме нормализации, поскольку атрибут «название товара» зависит от идентификатора продукта, но не от номера заказа:
- Номер заказа (первичный ключ);
- ID товара (первичный ключ);
- Название товара.
Третья форма нормализации
Третья форма нормализации (3NF): каждый не ключевой столбец должен быть независим от любого другого столбца. Если при проектировании реляционной базы данных изменение значения в одном не ключевом столбце вызывает изменение другого значения, эта таблица не соответствует третьей форме нормализации.
В соответствии с 3NF, нельзя хранить в таблице любые производные данные, такие как столбец «Налог», который в приведенном ниже примере, напрямую зависит от общей стоимости заказа:
В свое время были предложены дополнительные формы нормализации. В том числе форма нормализации Бойса-Кодда, четвертая-шестая формы и нормализации доменного ключа, но первые три являются наиболее распространенными.
Многомерные данные
Некоторым пользователям может потребоваться доступ к нескольким разрезам одного типа данных, особенно в базах данных OLAP. Например, им может потребоваться узнать продажи по клиенту, стране и месяцу. В этой ситуации лучше создать центральную таблицу, на которую могут ссылаться таблицы клиентов, стран и месяцев. Например:
Виды баз данных и их структура, примеры
Выделяют несколько видов баз данных. Основными из них являются:
- Фактографическая, с краткой информацией об объектах какой-то системы, формат которой строго фиксирован.
- Документальная, включает документы разного вида, в том числе текстовые, графические, звуковые, мультимедийные.
- Распределенная, является базой данных с разными частями, которые хранятся на различных компьютерах, объединенных в сеть.
- Централизованная, представляет собой базу данных, местом хранения которой является один компьютер.
- Реляционная, имеет табличную организацию данных.
- Неструктурированная (NoSQL), является базой данных, в которой делается попытка решить проблемы масштабируемости и доступности с помощью атомарности и согласованности данных без четкой структуры.
Базы данных разных систем обладают неодинаковой структурой. Для ПЭВМ характерно использование реляционных баз данных с файлами в виде таблиц, в которых столбцы являются полями, а строки – записями. В базе данных находятся данные определенного множества объектов. Для каждой записи характерна информация по одному объекту. Такую базу определяют:
- имя файла;
- список полей;
- ширина полей.
В качестве примера можно привести школьную базу с данными «Ученик», «Класс», «Адрес». Также базой данных является расписание движения поездов или автобусов. В этом случае каждой строке соответствует запись с данными конкретного объекта. Возможные поля: номер рейса, маршрут, время отправления и прибытия. Классической базой данных является телефонный справочник.
Определение
Запрос к базе данных – предписание с указанием на данные, которые необходимы пользователю.
Примечание
В случае некоторых запросов требуется составление сложной программы. К примеру, для выполнения запроса к базе в виде автобусного расписания необходимо вычислить разницу в среднем интервале отправления транспорта из одного города во второй и из второго пункта в третий.
Существует три звена для создания приложения, с помощью которого можно просматривать и редактировать базы данных:
- набор данных;
- источник информации;
- визуальные компоненты управления.
В случае Access роль таких звеньев выполняют:
- Table.
- DataSource.
- DBGrid.
Приложения базы данных является нитью, которая связывает базу и пользователя:
БД => набор данных –=> источник данных => визуальные компоненты => пользователь
Набор данных:
- Table, в виде таблицы, навигационного доступа;
- Query, включая запрос, реляционный доступ.
Визуальными компонентами являются:
- Сетки DBGrid, DBCtrlGrid.
- Навигатор DBNavigator.
- Разные аналоги Lable, Edit.
- Компоненты подстановки.
Access характеризуется наличием следующих типов полей:
- текстовый, в виде текстовой строки с максимальной длиной до 255, заданной параметром «размер»;
- поле МЕМО, является текстом длиной до 65535 символов;
- числовой, в параметре «Размер поля» можно задать поле: байт, целое, действительное и другие;
- дата/время, необходимо для записи данных о времени;
- денежный, является специальным форматом для решения финансовых задач;
- счетчик, в виде автоинкрементного поля, который предназначен для ключевого поля, увеличивается на единицу после добавления новой записи и сохраняется в данное поле новой записи, что гарантирует разные значения для неодинаковых записей;
- логический, в виде «да или нет», «правда или ложь», «включен или выключен»;
- объект OLE, предназначен для хранения документов, картинок, звуков и другой информации, представляет собой частный случай BLOB, то есть полей (Binary Large Object), которые можно встретить в разных базах данных;
- гиперссылка, необходима для хранения ссылок на ресурсы в Интернете, характерна не для всех форматов баз данных, например, отсутствует в dBase и Paradox;
- подстановка.
Благодаря связи с обеспечением целостности таблиц осуществляется контроль удаления и модификации данных. С помощью монопольного доступа к базам данных в них производят фундаментальные изменения.
Сравниваем три модели баз данных
Первая, иерархическая модель данных, имеет древовидную структуру («родитель-потомок»), и поддерживает только отношения типа «один к одному» или «один ко многим». Эта модель позволяет быстро получать данные, но не отличается гибкостью. Иногда роль элемента (родителя или потомка) неясна и не подходит для иерархической модели.
Вторая, сетевая модель данных, имеет более гибкую структуру, чем иерархическая модель данных, и поддерживает отношения «многие ко многим». Но быстро становится слишком сложной и неудобной для управления.
Третья модель — реляционная — более гибкая, чем иерархическая и проще для управления, чем сетевая. Реляционная модель сегодня используется чаще всего.
Объект в реляционной модели баз данных определяется как позиция информации, хранимой в базе данных. Объект может быть осязаемым или неосязаемым. Примером осязаемого объекта может быть сотрудник организации, а примером неосязаемой сущности — учётная запись покупателя. Объекты определяются атрибутами — информационным отображением свойств объекта. Эти атрибуты также известны как столбцы, а группа столбцов — как ряд. Ряд также можно определить как экземпляр объекта.
Объекты связываются отношениями, основные типы которых можно определить следующим образом:
«Один к одному»
В этом виде отношений один объект связан с другим. Например, Менеджер -> Отдел.
У каждого менеджера может быть только один отдел, и наоборот.
«Один ко многим»
В моделях данных отношение одного объекта с несколькими. Например, Сотрудник -> Отдел.
Каждый сотрудник может быть только в одном отделе, но в самом отделе может быть больше одного сотрудника.
«Многие ко многим»
В заданный момент времени объект может быть связан с любым другим. Например, Сотрудник -> Проект.
Сотрудник может участвовать в нескольких проектах, и каждый проект может объединять несколько сотрудников.
В реляционной модели объекты и их отношения представлены двухмерным массивом или таблицей.
Каждая таблица представляет объект.
Каждая таблица состоит из рядов и столбцов.
Отношения между объектами представлены столбцами.
Каждый столбец представляет атрибут объекта.
Значения столбцов выбираются из области или набора всех возможных значений.
Столбцы, которые используются для связи объектов, называются ключевыми. Есть два типа ключей — первичные и внешние.
Первичные служат для однозначного определения объекта. Внешний ключ — это первичный ключ одного объекта, существующий как атрибут в другой таблице.
Преимущества реляционной модели данных:
- Простота использования.
- Гибкость.
- Независимость данных.
- Безопасность.
- Простота практического применения.
- Слияние данных.
- Целостность данных.
Недостатки:
- Избыточность данных.
- Низкая производительность.
Таблица
Таблица представляет собой структуру данных, которая организует информацию в строки и столбцы. Может использоваться как для хранения, так и для отображения значений в структурированном формате. Базы хранят контент в таблицах, чтобы можно было быстро получить доступ к информации из определенных строк. Сайты часто используют их для отображения нескольких строк на странице.
Основные тип баз данных часто содержат несколько таблиц, каждая из которых предназначена для определенной цели. Например, информационная база компании может содержать отдельные таблицы для сотрудников, клиентов и поставщиков. Каждая из них может включать в себя собственный набор полей, основываясь на данных, которые должны в ней храниться. В таблицах информационной базы каждое поле считается столбцом, а каждая запись — строкой. Конкретное значение можно получить, запросив информацию из отдельного столбца и строки.
Иерархическая база данных
Под иерархической понимается такая база данных, в которой хранение данных и их структурирование осуществляется по принципу разделения элементов на родительские и дочерние. Преимуществом таких баз является лёгкость в чтении запрашиваемой информации и её быстрое предоставление пользователю.
Компьютер способен быстро ориентироваться в ней. Иерархический принцип взят за основу в структурировании файлов и папок в операционной системе Windows, а реестр хранит информацию о параметрах работы тех или иных приложений в структурированном иерархическим способом виде.
Все интернет-ресурсы также построены по иерархическому принципу, так как при его использовании ориентироваться в рамках сайта очень легко.
В качестве примера можно привести базу данных на языке XML, содержащую в себе очерки о состоянии сельского хозяйства в регионах России. В этом случае родительским элементом выступит государство, далее пойдёт разделение на субъекты, а в рамках субъектов будет своё разветвление. В данном случае от верхнего элемента к нижнему идёт строго одно обращение.
Шаг 2. Избавляемся от дубликатов в столбцах
Как было оговорено выше, столбцы “username” и “following_username” содержат дубликаты данных. Они возникли в результате того, что я хотел отобразить отношения между твиттами и пользователями. Давайте улучшим нашу структуру БД, разделив существующую таблицу на две: в одной будем хранить информацию, а в другой — отношения между записями.
Поскольку @Brett_Englebert подписан на @RealSkipBayless, то в таблице “following” отобразим это следующим образом: имя @Brett_Englebert поместим в колонку “from_user”, а @RealSkipBayless в “to_user.” Давайте посмотрим, как будет выглядеть таблица “following” после разделения Таблицы 1:
Таблица 2. following
| from_user | to_user |
|---|---|
| _DreamLead | Scootmedia |
| _DreamLead | MetiersInternet |
| GunnarSvalander | klout |
| GunnarSvalander | zillow |
| GEsoftware | DayJobDoc |
| GEsoftware | byosko |
| adrianburch | CindyCrawford |
| adrianburch | Arjantim |
| AndyRyder | MichaelDell |
| AndyRyder | Yahoo |
| Brett_Englebert | RealSkipBayless |
| Brett_Englebert | stephenasmith |
| NimbusData | dellock6 |
| NimbusData | rohitkilam |
| SSWUGorg | drsql |
| SSWUGorg | steam_games |
Таблица 3. users
| full_name | username | text | created_at |
|---|---|---|---|
| Boris Hadjur | _DreamLead | What do you think about #emailing #campaigns #traffic in #USA? Is it a good market nowadays? do you have #databases? | Tue, 12 Feb 2013 08:43:09 +0000 |
| Gunnar Svalander | GunnarSvalander | Bill Gates Talks Databases, Free Software on Reddit http://t.co/ShX4hZlA #billgates #databases | Tue, 12 Feb 2013 07:31:06 +0000 |
| GE Software | GEsoftware | RT @KirkDBorne: Readings in #Databases: excellent reading list, many categories: http://t.co/S6RBUNxq via @rxin Fascinating. | Tue, 12 Feb 2013 07:30:24 +0000 |
| Adrian Burch | adrianburch | RT @tisakovich: @NimbusData at the @Barclays Big Data conference in San Francisco today, talking #virtualization, #databases, and #flash memory. | Tue, 12 Feb 2013 06:58:22 +0000 |
| Andy Ryder | AndyRyder5 | http://t.co/D3KOJIvF article about Madden 2013 using AI to prodict the super bowl #databases #bus311 | Tue, 12 Feb 2013 05:29:41 +0000 |
| Andy Ryder | AndyRyder5 | http://t.co/rBhBXjma an article about privacy settings and facebook #databases #bus311 | Tue, 12 Feb 2013 05:24:17 +0000 |
| Brett Englebert | Brett_Englebert | #BUS311 University of Minnesota’s NCFPD is creating #databases to prevent “food fraud.” http://t.co/0LsAbKqJ | Tue, 12 Feb 2013 01:49:19 +0000 |
| Brett Englebert | Brett_Englebert | #BUS311 companies might be protecting their production #databases, but what about their backup files? http://t.co/okJjV3Bm | Tue, 12 Feb 2013 01:31:52 +0000 |
| Nimbus Data Systems | NimbusData | @NimbusData CEO @tisakovich @BarclaysOnline Big Data conference in San Francisco today, talking #virtualization, #databases,& #flash memory | Mon, 11 Feb 2013 23:15:05 +0000 |
| SSWUG.ORG | SSWUGorg | Don’t forget to sign up for our FREE expo this Friday: #Databases, #BI, and #Sharepoint: What You Need to Know! http://t.co/Ijrqrz29 | Mon, 11 Feb 2013 22:15:37 +0000 |
Уже лучше. Теперь в таблице “users” (Таблица 3) у нас хранится только информация о твиттах, а в таблице following (Таблица 2) — зависимость пользователей.
Основатель теории реляционных баз данных, Эдгар Кодд, назвал бы этот процесс (удаления повторений из столбцов таблиц) приведением БД к первой нормальной форме.
Шаг 3. Удаление повторений из строк
Теперь мы займёмся устранением других проблем, а именно, избавимся от дубликатов в строках таблицы “users”. Поскольку пользователи @AndyRyder5 и @Brett_Englebert разместили по несколько твиттов, то их имена в таблице “users” (Таблица 3) дублируются в колонке full_name. Данная проблема также решается разделением таблицы “users”.
Поскольку текст твитта и время его создания являются уникальными данными, то их мы поместим в одну и ту же таблицу. Также нам нужно указать связь между твитами и пользователями. Для этого я создал специальный столбец username.
Таблица 4. tweets
| username | text | created_at |
|---|---|---|
| _DreamLead | What do you think about #emailing #campaigns #traffic in #USA? Is it a good market nowadays? do you have #databases? | Tue, 12 Feb 2013 08:43:09 +0000 |
| GunnarSvalander | Bill Gates Talks Databases, Free Software on Reddit http://t.co/ShX4hZlA #billgates #databases | Tue, 12 Feb 2013 07:31:06 +0000 |
| GEsoftware | RT @KirkDBorne: Readings in #Databases: excellent reading list, many categories: http://t.co/S6RBUNxq via @rxin Fascinating. | Tue, 12 Feb 2013 07:30:24 +0000 |
| adrianburch | RT @tisakovich: @NimbusData at the @Barclays Big Data conference in San Francisco today, talking #virtualization, #databases, and #flash memory. | Tue, 12 Feb 2013 06:58:22 +0000 |
| AndyRyder5 | http://t.co/D3KOJIvF article about Madden 2013 using AI to prodict the super bowl #databases #bus311 | Tue, 12 Feb 2013 05:29:41 +0000 |
| AndyRyder5 | http://t.co/rBhBXjma an article about privacy settings and facebook #databases #bus311 | Tue, 12 Feb 2013 05:24:17 +0000 |
| Brett_Englebert | #BUS311 University of Minnesota’s NCFPD is creating #databases to prevent “food fraud.” http://t.co/0LsAbKqJ | Tue, 12 Feb 2013 01:49:19 +0000 |
| Brett_Englebert | #BUS311 companies might be protecting their production #databases, but what about their backup files? http://t.co/okJjV3Bm | Tue, 12 Feb 2013 01:31:52 +0000 |
| NimbusData | @NimbusData CEO @tisakovich @BarclaysOnline Big Data conference in San Francisco today, talking #virtualization, #databases,& #flash memory | Mon, 11 Feb 2013 23:15:05 +0000 |
| SSWUGorg | Don’t forget to sign up for our FREE expo this Friday: #Databases, #BI, and #Sharepoint: What You Need to Know! http://t.co/Ijrqrz29 | Mon, 11 Feb 2013 22:15:37 +0000 |
Таблица 5. users
| full_name | username |
|---|---|
| Boris Hadjur | _DreamLead |
| Gunnar Svalander | GunnarSvalander |
| GE Software | GEsoftware |
| Adrian Burch | adrianburch |
| Andy Ryder | AndyRyder5 |
| Brett Englebert | Brett_Englebert |
| Nimbus Data Systems | NimbusData |
| SSWUG.ORG | SSWUGorg |
После разделения в таблице users (Таблица 5) у нас присутствуют уникальные (не повторяющиеся) строки.
Данный процесс удаления дубликатов из строк называется приведением ко второй нормальной форме.
Применение таблиц
Веб-сайты часто используют таблицы для отображения данных в структурированном формате. HTML имеет тег <table>, а также теги <tr> и <td> для указания строк и столбцов. Поскольку во многих таблицах используется верхняя строка для информации заголовка, HTML также поддерживает тег <th>, используемый для определения ячеек в строке заголовка. При наличии таблицы на веб-странице большие объемы данных могут отображаться в удобном для чтения формате. На начальной стадии развития таблицы HTML использовались для построения общей компоновки веб-страниц. Однако каскадные таблицы стилей (CSS) со временем заменили этот инструмент и стали предпочтительным средством проектирования макетов.
Таблицы хранят и отображают данные в табличном формате. Такие программы, как Microsoft Excel и Apple Numbers предоставляют сетку или матрицу ячеек, в которой пользователи могут вводить значения. Каждая ячейка определяется парой строк или столбцов, такой как A3, она относится к ячейке в первом столбце и третьей строке таблицы. Форматируя данные, приложения электронных таблиц обеспечивают простой способ ввода и обмена информацией.
Отношения между таблицами
Отношения между таблицами устанавливают связь между данными, находящимися в разных таблицах реляционной базы данных.
Один-к-одному
Если между двумя таблицами существует отношение один-к-одному, то это означает, что каждая запись в одной таблице соответствует только одной записи в другой таблице.
Один-ко-многим
Когда объект, описываемый в одной из таблиц, имеет отношение к нескольким записям другой таблицы, возникает отношение «один-ко-многим». Этот тип отношения между таблицами наиболее часто встречается при проектировании структуры баз данных.
Много-ко-многим
При отношении между двумя таблицами много-ко-многим каждая запись в одной таблице связана с несколькими записями в другой таблице. Для удобства работы с таблицами, имеющими такие отношения, обычно в базу данных добавляют ещё одну таблицу, которая находится в отношении один-ко-многим и много-к-одному к соответствующим таблицам.
О выборе SQL-баз данных
- Необходимость соответствия базы данных требованиям ACID (Atomicity, Consistency, Isolation, Durability — атомарность, непротиворечивость, изолированность, долговечность). Это позволяет уменьшить вероятность неожиданного поведения системы и обеспечить целостность базы данных. Достигается подобное путём жёсткого определения того, как именно транзакции взаимодействуют с базой данных. Это отличается от подхода, используемого в NoSQL-базах, которые ставят во главу угла гибкость и скорость, а не 100% целостность данных.
- Данные, с которыми вы работаете, структурированы, при этом структура не подвержена частым изменением. Если ваша организация не находится в стадии экспоненциального роста, вероятно, не найдётся убедительных причин использовать БД, которая позволяет достаточно вольно обращаться с типами данных и нацелена на обработку огромных объёмов информации.
Отношения между таблицами
Чтобы база данных стала реляционной, одних данных мало. Между ними нужны еще и связи (те самые relations, от которых и пошло слово «реляционный»).
Для связи между таблицами служит так называемый внешний ключ (foreign key). Название довольно точно выражает его суть. Если в таблице A есть столбец для хранения первичного ключа таблицы B, то такой столбец и называется внешним ключом. Первичные и внешние ключи устанавливают связи между таблицами, превращая набор таблиц в цельную конструкцию — реляционную базу данных.
Приведу пример. Допустим, мы создали еще одну простую таблицу — справочник товаров. Назовем ее GOODS.
| Товарный справочник GOODS | ||||
| ID | NAME | PRICE | UNIT | COUNTRY |
| 1 | Яблоки | 50.00 | кг | Россия |
| 2 | Груши | 60.40 | кг | Франция |
| 3 | Апельсины | 40.00 | кг | Марокко |
| 4 | Макароны | 21.00 | шт | Франция |
| 5 | Кефир | 25.30 | шт | Россия |
| 6 | Молоко | 30.50 | шт | Россия |
Ее колонки: ID — первичный ключ, NAME — название товара, PRICE — его цена, UNIT — краткое название единицы измерения, COUNTRY — название страны-производителя.
Хорошо ли построена такая таблица? Вроде бы всем упоминавшимся выше принципам она удовлетворяет: уникальные имена столбцов с однородными данными, строки с уникальным первичным ключом. Казалось бы, все на месте. Тем не менее построена она непрофессионально. Здесь мы подходим к принципам, о которых я еще не упоминал, — к понятию о нормализации таблиц. Суть в том, чтобы всюду, где только можно, избегать избыточности в хранении данных путем выделения их в отдельные таблицы.
Посмотрим на нашу таблицу GOODS. Чем она плоха? Представьте себе, что завтра придется изменить название какой-нибудь страны. Такое случается часто. Бирма когда-то меняла свое название на Мьянму, Польша — на Польскую Республику. Хочется ли вам менять огромное количество строк во всех таблицах, где эти страны упоминаются? Представьте также, что вас попросят отобрать запросом весь штучный товар. Можете ли вы быть уверены в том, что оператор всюду набил эту аббревиатуру правильно и одинаково? Скорее всего, окажется, что в таблице встречаются все мыслимые вариации: «шт», «Шт», «шт.», «штук» и «штуки».
Думаю, проблема понятна. Выходом из этой ситуации будет выделение из нее двух других таблиц: справочника стран (COUNTRIES) и справочника единиц измерений (UNITS).
| Справочник единиц измерения UNITS | ||
| ID | NAME | SHORT_NAME |
| 1 | Штуки | шт |
| 2 | Килограммы | кг |
Сам справочник товаров GOODS будет теперь выглядеть совершенно по-другому (см. таблицу).
| Товарный справочник GOODS после нормализации | ||||
| ID | NAME | PRICE | UNIT_ID | COUNTRY_ID |
| 1 | Яблоки | 50.00 | 2 | 1 |
| 2 | Груши | 60.40 | 2 | 2 |
| 3 | Апельсины | 40.00 | 2 | 3 |
| 4 | Макароны | 21.00 | 1 | 2 |
| 5 | Кефир | 25.30 | 1 | 1 |
| 6 | Молоко | 30.50 | 1 | 1 |
Что изменилось? Вместо столбцов с названиями единиц измерения и стран появились столбцы UNIT_ID и COUNTRY_ID с кодами, отсылающими нас к другим таблицам. Это и есть внешние ключи. Что означает значение 2 в столбце UNIT_ID? Оно означает, что интересующая нас информация по единице измерения находится той строке таблицы UNITS, где ID = 2. Достаточно заглянуть в этот справочник, чтобы убедиться, что называется эта единица полностью «штуки», а кратко — «шт».
Объяснение всех видов и принципов нормализации выходит далеко за рамки данной статьи. Главное — почувствовать общие принципы. Единожды научившись строить базы данных правильно, вы уже не сможете иначе. Для этого не обязательно знать теорию в полном объеме — зачастую здравого смысла и интуиции бывает достаточно.
Вернемся к нашей маленькой базе данных. Ну хорошо, нормализовали мы таблицу. Сможем теперь менять названия стран, не исправляя всю таблицу. Замечательно. Но как теперь увидеть эти названия? Ведь в справочнике товаров появились коды, и таблица сразу потеряла свою наглядность.
Вот тут-то мы и подходим к понятию уже не раз упоминавшихся запросов, которые, используя связи, извлекают из них нужную информацию и выдают нам опять же в виде так называемой отчетной таблицы.
PostgreSQL
PostgreSQL является еще одним выдающимся решением с открытым исходным кодом, работающим во всех основных операционных системах, включая Linux, UNIX (AIX, BSD, HP-UX, SGI IRIX, Mac OS X, Solaris, Tru64) и Windows. PostgreSQL полностью отвечает принципам ACID (атомарность, согласованность, изолированность, устойчивость).
Достоинства
- Возможность создания пользовательских типов данных и методов запросов;
- Среда разработки баз данных выполняет хранимые процедуры более чем на десятке языков программирования: Java, Perl, Python, Ruby, Tcl, C/C ++ и собственный PL/pgSQL;
- GiST (система обобщенного поиска): объединяет различные алгоритмы сортировки и поиска: B-дерево, B+-дерево, R-дерево, деревья частичных сумм и ранжированные B+ -деревья;
- Возможность создания для большего параллелизма без изменения кода Postgres, например, CitusDB.
Недостатки
- Система MVCC требует регулярной «чистки»: проблемы в средах с высокой скоростью транзакций;
- Разработка осуществляется обширным сообществом: слишком много усилий для улучшений.
Базы данных с широкими столбцами
Эти базы данных хранят данные в виде записей ключ / значение на жестком диске или твердотельном накопителе. Эти решения предназначены для достаточно хорошего масштабирования, чтобы управлять петабайтами данных на тысячах общих серверов в распределенной системе. Они представляют архитектуру SSTable. Эта архитектура была разработана для двух случаев использования: быстрый доступ к ключу и быстрая запись с высокой доступностью.
Достоинства:
- Быстрая запись построчно
- Быстрое чтение по ключу
- Хорошая масштабируемость
- Высокая доступность
Недостатки:
- Формат «ключ-значение»
- Нет поддержки аналитики
Примеры: Cassandra, HBase.
Создание связей между сущностями
Теперь, когда данные преобразованы в таблицы, нужно проанализировать связи между ними. Сложность базы данных определяется количеством элементов, взаимодействующих между двумя связанными таблицами. Определение сложности помогает убедиться, что вы разделили данные на таблицы наиболее эффективно.
Каждый объект может быть взаимосвязан с другим с помощью одного из трех типов связи:
Связь «один-к одному»
Когда существует только один экземпляр объекта A для каждого экземпляра объекта B, говорят, что между ними существует связь «один-к одному» (часто обозначается 1:1). Можно указать этот тип связи в ER-диаграмме линией с тире на каждом конце:
Если при проектировании и разработке баз данных у вас нет оснований разделять эти данные, связь 1:1 обычно указывает на то, что в лучше объединить эти таблицы в одну.
Но при определенных обстоятельствах целесообразнее создавать таблицы со связями 1:1. Если есть поле с необязательными данными, например «описание», которое не заполнено для многих записей, можно переместить все описания в отдельную таблицу, исключая пустые поля и улучшая производительность базы данных.
Чтобы гарантировать, что данные соотносятся правильно, в нужно будет включить, по крайней мере, один идентичный столбец в каждой таблице. Скорее всего, это будет первичный ключ.
Связь «один-ко-многим»
Эта связи возникают, когда запись в одной таблице связана с несколькими записями в другой. Например, один клиент мог разместить много заказов, или у читателя может быть сразу несколько книг, взятых в библиотеке. Связи «один- ко-многим» (1:M) обозначаются так называемой «меткой ноги вороны», как в этом примере:
Чтобы реализовать связь 1:M, добавьте первичный ключ из «одной» таблицы в качестве атрибута в другую таблицу. Если первичный ключ таким образом указан в другой таблице, он называется внешним ключом. Таблица со стороны связи «1» представляет собой родительскую таблицу для дочерней таблицы на другой стороне.
Связь «многие-ко-многим»
Когда несколько объектов таблицы могут быть связаны с несколькими объектами другой. Говорят, что они имеют связь «многие-ко-многим» (M:N). Например, в случае студентов и курсов, поскольку студент может посещать много курсов, и каждый курс могут посещать много студентов.
На ER-диаграмме эти связи отображаются с помощью следующих строк:
При проектировании структуры базы данных реализовать такого рода связи невозможно. Вместо этого нужно разбить их на две связи «один-ко-многим».
Для этого нужно создать между этими двумя таблицами новую сущность. Если между продажами и продуктами существует связь M:N, можно назвать этот новый объект «sold_products», так как он будет содержать данные для каждой продажи. И таблица продаж, и таблица товаров будут иметь связь 1:M с sold_products. Этот вид промежуточного объекта в различных моделях называется таблицей ссылок, ассоциативным объектом или таблицей связей.
Каждая запись в таблице связей будет соответствовать двум сущностям из соседних таблиц. Например, таблица связей между студентами и курсами может выглядеть следующим образом:
Обязательно или нет?
Другим способом анализа связей является рассмотрение того, какая сторона связи должна существовать, чтобы существовала другая. Необязательная сторона может быть отмечена кружком на линии. Например, страна должна существовать для того, чтобы иметь представителя в Организации Объединенных Наций, а не наоборот:
Два объекта могут быть взаимозависимыми (один не может существовать без другого).
Рекурсивные связи
Иногда при проектировании базы данных таблица указывает на себя саму. Например, таблица сотрудников может иметь атрибут «руководитель», который ссылается на другое лицо в этой же таблице. Это называется рекурсивными связями.
Лишние связи
Лишние связи — это те, которые выражены более одного раза
Как правило, можно удалить одну из таких связей без потери какой-либо важной информации. Например, если объект «ученики» имеет прямую связь с другим объектом, называемым «учителя», но также имеет косвенные отношения с учителями через «предметы», нужно удалить связь между «учениками» и «учителями»
Так как единственный способ, которым ученикам назначают учителей — это предметы.
5 последних уроков рубрики «Разное»
-
Выбрать хороший хостинг для своего сайта достаточно сложная задача. Особенно сейчас, когда на рынке услуг хостинга действует несколько сотен игроков с очень привлекательными предложениями. Хорошим вариантом является лидер рейтинга Хостинг Ниндзя — Макхост.
-
Как разместить свой сайт на хостинге? Правильно выбранный хороший хостинг — это будущее Ваших сайтов
Проект готов, Все проверено на локальном сервере OpenServer и можно переносить сайт на хостинг. Вот только какую компанию выбрать? Предлагаю рассмотреть хостинг fornex.com. Отличное место для твоего проекта с перспективами бурного роста.
-
Создание вебсайта — процесс трудоёмкий, требующий слаженного взаимодействия между заказчиком и исполнителем, а также между всеми членами коллектива, вовлечёнными в проект. И в этом очень хорошее подспорье окажет онлайн платформа Wrike.
-
Подборка из нескольких десятков ресурсов для создания мокапов и прототипов.








