Основы linux от основателя gentoo. часть 2 (1/5): регулярные выражения
Содержание:
2. Примеры использования команды Grep
Теперь мы увидим, как использовать команду Grep в Linux.
Как использовать Grep в общем
Чтобы понять, как работает Grep, мы посмотрим в каталоге / etc / passwd все результаты, связанные с нашим пользователем:
grep solvetic / etc / passwd
В качестве дополнительного момента помните, что можно сказать, что grep игнорирует прописные и строчные буквы в результатах, для этого мы выполним следующее:
grep -i "resoltic" / etc / passwd
Grep идеально подходит для поиска определенных терминов в известных файлах, например, мы выполним следующий поиск:
grep Solvetic Solvetic.txt
Этот же термин можно искать в разных файлах одновременно, для этого мы будем использовать следующую строку:
grep Solvetic Solvetic.txt Solvetic1.txt
Более сокращенный способ сделать это — выполнить следующее:
grep solvetic *. *
Как использовать grep для перенаправления результатов в файл в Linux
Это полезно в тех случаях, когда мы должны выполнить административные задачи над файлами позже, поэтому можно перенаправить вывод команды grep в определенный файл, например, мы сделаем следующее:
grep Solvetic Solvetic.txt> Solvetic2.txt
Как использовать grep для поиска в каталогах
Благодаря параметру -r мы сможем найти значение в доступных подкаталогах, выполним следующее:
grep -r Solvetic / домашний / решающий
Как использовать grep для отображения номера строки
Для задач аудита или расширенной поддержки идеально отображать номер строки, в которой находится указанный шаблон поиска, для этого мы можем использовать параметр -n следующим образом. Там мы находим номер строки, где находится каждое значение.
grep -n Solvetic Solvetic.txt
Как использовать grep для выделения результатов
Поскольку мы знаем, что текст во многих случаях может сбить с толку, по этой причине решение состоит в том, чтобы выделить критерии поиска, которые фокусируют наше представление непосредственно на этой строке, для этого мы будем использовать параметр цвета, например:
grep -color Solvetic Solvetic.txt
Как использовать grep для отображения строк, начинающихся или заканчивающихся указанным шаблоном
Мы можем захотеть визуализировать только результаты строк, которые начинаются или заканчиваются критериями поиска, для этого, если мы хотим найти строки, которые начинаются, мы будем использовать следующую строку:
grep ^ Solvetic Solvetic.txt
Теперь, чтобы отобразить строки, которые заканчиваются, мы будем использовать следующее:
grep Solvetic $ Solvetic.txt
Как использовать grep для печати всех строк, не видя совпадающих
Если мы хотим увидеть все строки, кроме тех, где задано желаемое значение, мы должны использовать параметр -v следующим образом:
grep -v Solvetic Solvetic.txt
Как использовать grep с другими командами
Grep, как и многие команды Linux, можно использовать одновременно с другими командами для получения более четких результатов, например, если мы хотим развернуть процессы HTTP, мы будем использовать grep рядом с ps следующим образом:
ps -ef | grep http
Как использовать grep, чтобы посчитать, сколько слов повторяется в файле
Если мы хотим узнать, сколько раз шаблон повторяется в данном файле, мы будем использовать параметр -c:
grep -c Solvetic Solvetic.txt
Как использовать grep для обратного поиска
Хотя это звучит странно, это не что иное, как отображение в результате слов, которые мы не указываем, это достигается с помощью параметра -v:
grep -v Solvetic Solvetic2.txt
Как использовать grep для просмотра сведений об оборудовании
Ранее мы видели, что мы можем комбинировать grep с другими командами для отображения результата, ну, если мы хотим получить конкретные сведения об оборудовании, мы можем использовать cat с grep следующим образом:
cat / proc / cpuinfo | grep -i 'Модель'
Во всем мире мы узнали, как использовать команду grep для доступа к гораздо более конкретным результатам поиска в Linux.
Примеры команды grep в Linux и Unix
Ниже приведены некоторые стандартные команды grep, объясненные с примерами, которые помогут вам начать работу с grep в Linux, macOS и Unix:
- Найдите любую строку, которая содержит слово в имени файла в Linux: grep 'word' filename
- Выполните поиск слова ‘bar’ без учета регистра в Linux и Unix: grep -i 'bar' file1
- Найдите все файлы в текущем каталоге и во всех его подкаталогах в Linux по слову httpd: grep -R 'httpd' .
- Найдите и отобразите общее количество раз, когда строка ‘nixcraft’ появляется в файле с именем frontpage.md:: grep -c 'nixcraft' frontpage.md
Давайте подробно рассмотрим все команды и параметры.
Синтаксис
Синтаксис grep следующий:
grep 'word' filename fgrep 'word-to-search' file.txt grep 'word' file1 file2 file3 grep 'string1 string2' filename cat otherfile | grep 'something' command | grep 'something' command option1 | grep 'data' grep --color 'data' fileName grep -options pattern filename fgrep -options words file |
grep ‘word’ filename fgrep ‘word-to-search’ file.txt grep ‘word’ file1 file2 file3 grep ‘string1 string2’ filename cat otherfile | grep ‘something’ command | grep ‘something’ command option1 | grep ‘data’ grep —color ‘data’ fileName grep pattern filename fgrep words file
grep — что это и зачем может быть нужно
Про «репку» (как я её называю) почему-то в курсе не многие, что печалит. «Унылая» (не в обиду) формулировка из Википедии звучит примерно так:
grep — утилита командной строки, которая находит на вводе строки, отвечающие заданному регулярному выражению, и выводит их, если вывод не отменён специальным ключом.
Не сильно легче, но доступнее, можно сформулировать так:
grep — утилита командной строки, используется для поиска и фильтрации текста в файлах, на основе шаблона, который (шаблон) может быть регулярным выражением.
Если всё еще ничего не понятно, то условно говоря это удобный поиск текста везде и всюду, в особенности в файлах, директория в и тп. Удобно распарсивать логи и их содержимое, не прибегая к софту, как это бывает в Windows.
Справку можно вычленить так же как по find, т.е методом pgrep, fgrep, egrep и черт знает что еще:
Или:
Расписывать все ключи и даже основные тут (вы еще помните, что это блоговая часть сайта?) не буду, так как в отличии от find’а, последних тут вообще страшное подмножество, особенно учитывая, что существуют pgrep, fgrep, egrep и черт знает что еще, которые, в некотором смысле тоже самое, но для определенных целей.
Потрясающе удобная штука, которая жизненно необходима, особенно, если Вы что-то когда-то где-то зачем-то администрировали. Взглянем на примеры.
Команды для управления сетью
В стандартный функционал «Терминала» входит и просмотр данных по параметрам сети, скорости и качестве передачи данных.
- ip – команда для работы с сетью, благодаря наличию множества опций она многофункциональна. К примеру, добавив функцию address show, можно посмотреть информацию о сетевых адресах, а с route управлять маршрутизацией.
- ping – помогает определить качество подключения к сети или наличие его как такового.
- nethogs – выводит данные о количестве израсходованного трафика.
- traceroute – команда, аналогичная ping, но дополнительно дающая информацию о полном маршруте передачи пакетов, скорости доставки на каждом узле и так далее.
- mtr – мощная утилита для диагностики сети, совмещающая функционал команд ping и traceroute.
Примеры использования регулярных выражений
Теперь, когда мы рассмотрели основы и вы знаете как все работает, осталось закрепить полученные знания про регулярные выражения linux grep на практике. Два очень полезные спецсимвола — это ^ и $, которые обозначают начало и конец строки. Например, мы хотим получить всех пользователей, зарегистрированных в нашей системе, имя которых начинается на s. Тогда можно применить регулярное выражение «^s». Вы можете использовать команду egrep:

Если мы хотим отбирать строки по последнему символу в строке, что для этого можно использовать $. Например, выберем всех системных пользователей, без оболочки, записи о таких пользователях заканчиваются на false:

Чтобы вывести имена пользователей, которые начинаются на s или d используйте такое выражение:
 Такой же результат можно получить, использовав символ «|». Первый вариант более пригоден для диапазонов, а второй чаще применяется для обычных или/или:
Такой же результат можно получить, использовав символ «|». Первый вариант более пригоден для диапазонов, а второй чаще применяется для обычных или/или:

Теперь давайте выберем всех пользователей, длина имени которых составляет не три символа. Имя пользователя завершается двоеточием. Мы можем сказать, что оно может содержать любой буквенный символ, который должен быть повторен три раза, перед двоеточием:

Применение grep в Linux
Одна из более полезных и многофункциональных команд в терминале Linux – бригада «grep». Grep – это акроним, какой расшифровывается как «global regular expression print» (то имеется, «искать везде соответствующие постоянному выражению строки и выводить их»).
Это значит, что grep возможно использовать для того, чтобы проглядеть, соответствуют ли вводимые данные заданным шаблонам. В простенькой форме grep используется для розыска совпадений буквенных шаблонов в текстовом файле. Это значивает, что если команда grep приобретает слово для поиска, она будет выводить каждую сохраняющую это слово строку файла.
Назначение grep — поиск строк согласно условию, изображенному регулярным выражением. Существуют изменения классического grep — egrep, fgrep, rgrep. Все они отточены под конкретные цели, при этом способности grep перекрывают весь функционал. Самым несложным примером использования команды представляется вывод строки, удовлетворяющей шаблону, из файла. Пример мы хотим найти строку, сохраняющую ‘user’ в файле /etc/mysql/my.cnf. Для этого воспользуемся последующей командой:
Grep сможет просто искать конкретное словечко:
Или строку, но в таком варианте её нужно заключать в кавычки:
В добавление альтернативами программы являются egrep и fgrep, которые являются тем же самым, что и, соответственно, grep -E и grep -F. Варианты egrep и fgrep являются устаревшими, но работают для обратной совместимости. Вместо устаревших вариантов рекомендуется использовать grep -E и grep –F.
Команда grep сопоставляет строки исходных файлов с шаблоном, этим базовым регулярным выражением. Если файлы не указаны, используется стандартный ввод. Как как обычно каждая успешно сопоставленная строка копируется на стандартный вывод; если исходных файлов чуть-чуть, перед найденной строкой выдается имя файла. В качестве шаблонов воспринимаются базовые непрерывные выражения (выражения, имеющие своими значениями цепочки символов, и использующие ограниченный комплекс алфавитно-цифровых и специальных символов).
Other options
| —line-buffered | Use line buffering on output. This can cause a performance penalty. |
| —mmap | If possible, use the mmap system call to read input, instead of the default read system call. In some situations, —mmap yields better performance. However, —mmap can cause undefined behavior (including core dumps) if an input file shrinks while grep is operating, or if an I/O error occurs. |
| -U, —binary | Treat the file(s) as binary. By default, under MS-DOS and MS-Windows, grep guesses the file type by looking at the contents of the first 32 KB read from the file. If grep decides the file is a text file, it strips the CR characters from the original file contents (to make regular expressions with ^ and $ work correctly). Specifying -U overrules this guesswork, causing all files to be read and passed to the matching mechanism verbatim; if the file is a text file with CR/LF pairs at the end of each line, this causes some regular expressions to fail. This option has no effect on platforms other than MS-DOS and MS-Windows. |
| -z, —null-data | Treat the input as a set of lines, each terminated by a zero byte (the ASCII NUL character) instead of a newline. Like the -Z or —null option, this option can be used with commands like sort -z to process arbitrary file names. |
Output line prefix control
| -b, —byte-offset | Print the 0-based byte offset in the input file before each line of output. If -o (—only-matching) is specified, print the offset of the matching part itself. |
| -H, —with-filename | Print the file name for each match. This is the default when there is more than one file to search. |
| -h, —no-filename | Suppress the prefixing of file names on output. This is the default when there is only one file (or only standard input) to search. |
| —label=LABEL | Display input actually coming from standard input as input coming from file LABEL. This is especially useful when implementing tools like zgrep, e.g., gzip -cd foo.gz | grep —label=foo -H something. See also the -H option. |
| -n, —line-number | Prefix each line of output with the 1-based line number within its input file. |
| -T, —initial-tab | Make sure that the first character of actual line content lies on a tab stop, so that the alignment of tabs looks normal. This is useful with options that prefix their output to the actual content: -H, -n, and -b. To improve the probability that lines from a single file will all start at the same column, this also causes the line number and byte offset (if present) to be printed in a minimum size field width. |
| -u,—unix-byte-offsets | Report Unix-style byte offsets. This switch causes grep to report byte offsets as if the file were a Unix-style text file, i.e., with CR characters stripped off. This produces results identical to running grep on a Unix machine. This option has no effect unless -b option is also used; it has no effect on platforms other than MS-DOS and MS-Windows. |
| -Z, —null | Output a zero byte (the ASCII NUL character) instead of the character that normally follows a file name. For example, grep -lZ outputs a zero byte after each file name instead of the usual newline. This option makes the output unambiguous, even in the presence of file names containing unusual characters like newlines. This option can be used with commands like find -print0, perl -0, sort -z, and xargs -0 to process arbitrary file names, even those that contain newline characters. |
Как мне использовать grep для поиска файла в Linux?
Найдите /etc/passwd для пользователя boo, введите: Примеры выходных данных::
foo:x:1000:1000:boo,,,:/home/boo:/bin/ksh
Мы можем использовать fgrep/grep тобы найти все строки файла, содержащие определенное слово. Например, чтобы перечислить все строки файла с именем address.txt в текущем каталоге, которые содержат слово “California” выполните: Обратите внимание, что приведенная выше команда также возвращает строки, в которых “California” является частью других слов, например “Californication” или “Californian”. Следовательно, передайте -w параметр с помощью команды grep/fgrep чтобы получить только строки, в которых “California” включено как целое слово: Вы можете заставить grep игнорировать регистр слов, то есть сопоставить boo, Boo, BOO и все другие комбинации с -i параметром. Например, введите следующую команду:. Последнийgrep -i «boo» /etc/passwd
 Последнийgrep -i "boo" /etc/passwd
Последнийgrep -i "boo" /etc/passwd
Использование нескольких поисковых запросов
Параметр -E (расширенное регулярное выражение) позволяет искать несколько слов. (Параметр -E заменяет устаревший egrep версия grep.)
Эта команда выполняет поиск двух условий поиска: «средний» и «без памяти».
grep -E -w -i "average|memfree" geek-1.log

Все совпадающие строки отображаются для каждого условия поиска.
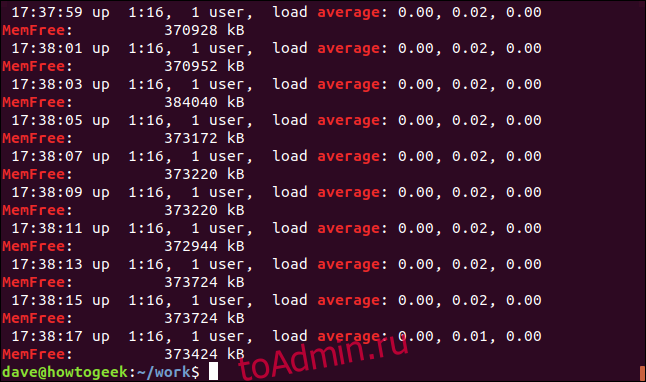
Вы также можете искать несколько терминов, которые не обязательно являются целыми словами, но могут быть и целыми словами.
Параметр -e (шаблоны) позволяет использовать несколько условий поиска в командной строке. Мы используем функцию скобок регулярного выражения для создания шаблона поиска. Он сообщает grep, что нужно сопоставить любой из символов, содержащихся в скобках «[]. » Это означает, что при поиске grep будет соответствовать либо «kB», либо «KB».

Обе строки совпадают, и на самом деле некоторые строки содержат обе строки.
11. Параметры для использования с командой Tree в Linux
Параметры для использования с деревом
Далее Solvetic объяснит доступные параметры для использования с Tree:
-a: распечатать все файлы, помните, что по умолчанию дерево не печатает скрытые файлы.
-d: список только каталогов.
-l: продолжить символические ссылки, если они указывают на каталоги, притворяясь каталогами.
-f: вывести префикс полного пути к объектам.
-x: остается только в текущей файловой системе.
-L Level: позволяет определить максимальную глубину просмотра дерева каталогов в результате.
-R: Действовать рекурсивно, пересекая дерево в каталогах каждого уровня, и в каждом из них оно будет выполняться. дерево снова, добавив `-o 00Tree.html ‘.
-P шаблон: список только файлов, которые соответствуют шаблону подстановки.
-I шаблон: не перечислять файлы, которые соответствуют шаблону подстановки.
—matchdirs. Этот параметр указывает шаблон соответствия, который позволяет применять шаблон только к именам каталогов.
—prune: этот параметр удаляет пустые каталоги из выходных данных.
—noreport: пропускает печать файла и отчета каталога в конце списка выполненного дерева.
Общие параметры дерева
Это общие параметры, доступные для дерева, но у нас также есть эксклюзивные параметры для файлов, это:
-q: печатать непечатаемые символы в именах файлов.
-N: печать непечатных символов.
-Q: его функция заключается в назначении имен файлов в двойных кавычках.
-p: вывести тип файла и разрешения для каждого файла в каталоге.
-u: распечатать имя пользователя или UID файла.
-s: вывести размер каждого файла в байтах, а также его имя.
-g Распечатать имя группы или GID файла.
-h: его функция — распечатывать размер каждого файла разборчиво для пользователя.
—du: Он действует в каждом каталоге, генерируя отчет о его размере, включая размеры всех его файлов и подкаталогов.
—si: он использует степени 1000 (единицы СИ) для отображения размера файла.
-D: Распечатать дату последнего изменения файлов.
-F: Ваша задача — добавить `/ ‘для каталогов, a` =’ для файлов сокетов, a` * ‘для исполняемых файлов, `>’ для дверей (Solaris) и a` | ‘ для FIFO.
—inodes: вывести номер инода файла или каталога.
- —device: вывести номер устройства, к которому относится файл или каталог в результате.
- -v: Сортировать вывод по версии.
-U: не упорядочивает результаты.
-r: сортировать вывод в обратном порядке.
-t: сортировать результаты по времени последней модификации, а не по алфавиту.
-S: активировать линейную графику CP437
-n: отключает раскраску результата.
-C: активирует раскраску.
-X: активировать вывод XML.
-J: активировать вывод JSON.
-H baseHREF: активирует вывод HTML, включая ссылки HTTP.
—help: Помощь дерева доступа.
—version: показывает используемую версию команды Tree.
С помощью этих двух команд стало возможным гораздо более полное администрирование каждой задачи, выполняемой над файлами в Linux, дополняющей задачи поиска или управления этими файлами и доступа к интегральным результатам по мере необходимости.
Checking for full words, not for sub-strings using grep -w
If you want to search for a word, and to avoid it to match the substrings use -w option. Just doing out a normal search will show out all the lines.
The following example is the regular grep where it is searching for «is». When you search for «is», without any option it will show out «is», «his», «this» and everything which has the substring «is».
$ grep -i "is" demo_file THIS LINE IS THE 1ST UPPER CASE LINE IN THIS FILE. this line is the 1st lower case line in this file. This Line Has All Its First Character Of The Word With Upper Case. Two lines above this line is empty. And this is the last line.
The following example is the WORD grep where it is searching only for the word «is». Please note that this output does not contain the line «This Line Has All Its First Character Of The Word With Upper Case», even though «is» is there in the «This», as the following is looking only for the word «is» and not for «this».
$ grep -iw "is" demo_file THIS LINE IS THE 1ST UPPER CASE LINE IN THIS FILE. this line is the 1st lower case line in this file. Two lines above this line is empty. And this is the last line.
Команды для управления пользователями
Linux — многопользовательская система. Ей одновременно могут управлять несколько людей. Поэтому здесь достаточно сложная система добавления и редактирования учетных записей.
- useradd — создает новую учетную запись. Например, мы хотим добавить пользователя с именем Timeweb. Для этого вводим: useradd Timeweb. Но свежесозданному аккаунту нужен не только логин, но и пароль. С помощью опций можно задать дополнительные характеристики новому пользователю.
- passwd — задает пароль для учетной записи, работает вкупе с предыдущей командой. То есть сразу после создания аккаунта, пишем: passwd Timeweb (в вашем случае может быть любой другой пользователь). После этого система попросит придумать и указать пароль для новой учетной записи. По ходу набора пароля в терминале не будут отображаться даже звездочки, но он все равно учитывает каждую нажатую клавишу. Продолжайте набирать пароль вслепую.
- userdel — удаляет выбранную учетную запись. Синтаксис простейший:
Technical description
grep searches the named input FILEs (or standard input if no files are named, or if a single dash («—«) is given as the file name) for lines containing a match to the given PATTERN. By default, grep prints the matching lines.
Also, three variant programs egrep, fgrep and rgrep are available:
- egrep is the same as running grep -E. In this mode, grep evaluates your PATTERN string as an extended regular expression (ERE). Nowadays, ERE does not «extend» very far beyond basic regular expressions, but they can still be very useful. For more information about extended regular expressions, see: , below.
- fgrep is the same as running grep -F. In this mode, grep evaluates your PATTERN string as a «fixed string» — every character in your string is treated literally. For example, if your string contains an asterisk («*«), grep will try to match it with an actual asterisk rather than interpreting this as a wildcard. If your string contains multiple lines (if it contains newlines), each line will be considered a fixed string, and any of them can trigger a match.
- rgrep is the same as running grep -r. In this mode, grep performs its search recursively. If it encounters a directory, it traverses into that directory and continue searching. (Symbolic links are ignored; if you want to search directories that are symbolically linked, use the -R option instead).
In older operating systems, egrep, fgrep and rgrep were distinct programs with their own executables. In modern systems, these special command names are shortcuts to grep with the appropriate flags enabled. They are functionally equivalent.
REGULAR EXPRESSIONS
grep understands three different versions of regular expression syntax: «basic» (BRE), «extended» (ERE) and «perl» (PRCE). In GNU grep, there is no difference
in available functionality between basic and extended syntaxes. In other implementations, basic regular expressions are less powerful. The following description applies to extended regular expressions; differences for basic regular expressions are
summarized afterwards. Perl regular expressions give additional functionality, and are documented in pcrepattern(3), but may not be available on every system.
The fundamental building blocks are the regular expressions that match a single character. Most characters, including all letters and digits, are regular expressions that match themselves. Any meta-character with special meaning may be quoted by
preceding it with a backslash.
The period . matches any single character.
Character Classes and Bracket Expressions
bracket expression^not
Within a bracket expression, a range expression consists of two characters separated by a hyphen. It matches any single character that sorts between the two characters, inclusive, using the locale’s collating sequence and character set. For
example, in the default C locale, is equivalent to . Many locales sort characters in dictionary order, and in these locales is typically not equivalent to ; it
might be equivalent to , for example. To obtain the traditional interpretation of bracket expressions, you can use the C locale by setting the LC_ALL environment variable to the value C.
Finally, certain named classes of characters are predefined within bracket expressions, as follows. Their names are self explanatory, and they are , , , , , , , , , , and . For example, ] means the character class of numbers and letters in the current locale. In the C locale and ASCII character set encoding, this is the same as . (Note that the brackets in
these class names are part of the symbolic names, and must be included in addition to the brackets delimiting the bracket expression.) Most meta-characters lose their special meaning inside bracket expressions. To include a literal place it first in the list. Similarly, to include a literal ^ place it anywhere but first. Finally, to include a literal — place it last.
Repetition
- ?
- The preceding item is optional and matched at most once.
- *
- The preceding item will be matched zero or more times.
- +
- The preceding item will be matched one or more times.
- {n}
- The preceding item is matched exactly n times.
- {n,}
- The preceding item is matched n or more times.
- {n,m}
- The preceding item is matched at least n times, but not more than m times.
Basic vs Extended Regular Expressions
?+{|()\?\+\{\|\(\)
Traditional egrep did not support the { meta-character, and some egrep implementations support \{ instead, so portable scripts should avoid { in grep -E patterns and should use to match a literal {.
GNU grep -E attempts to support traditional usage by assuming that { is not special if it would be the start of an invalid interval specification. For example, the command grep -E ‘{1’ searches for the two-character string {1 instead of reporting a syntax error in the regular expression. POSIX.2 allows this behavior as an extension, but portable
scripts should avoid it.
Difference between find and grep
For those just starting out on the Linux command line, it’s important to remember that find and grep are two commands with two very different functions, even though we use both to “find” something that the user specifies.
It’s handy to use grep to find a file when you use it to search through the output of the ls command as we showed in the first examples of the tutorial.
However, if you need to search recursively for the name of a file – or part of the file name if you use a wildcard (asterisk) – you’re much ahead to use the ‘find’ command.
$ find /path/to/search -name name-of-file
The output above shows that the find command was able to successfully locate the file we searched for.
Основы использования
В простейшей форме grep используется для поиска совпадений буквенных шаблонов в текстовом файле. Это значит, что если команда grep получает слово для поиска, она будет выводить каждую содержащую это слово строку файла.
В качестве примера можно использовать grep для поиска строк, содержащих слово «GNU» в версии 3 GNU General Public License на системе Ubuntu.
cd /usr/share/common-licenses grep «GNU» GPL-3 GNU GENERAL PUBLIC LICENSE The GNU General Public License is a free, copyleft license for the GNU General Public License is intended to guarantee your freedom to GNU General Public License for most of our software; it applies also to Developers that use the GNU GPL protect your rights with two steps: «This License» refers to version 3 of the GNU General Public License. 13. Use with the GNU Affero General Public License. under version 3 of the GNU Affero General Public License into a single . .
Первый аргумент, «GNU», является искомым шаблоном, а второй аргумент, «GPL-3», является входным файлом, который нужно найти.
В результате будут выведены все строки, содержащие текстовый шаблон. В некоторых дистрибутивах Linux искомый шаблон будет выделен в выведенных строках.
Общие опции
По умолчанию команда grep просто ищет строго указанные шаблоны во входном файле и выводит найденные строки. Тем не менее, поведение утилиты grep можно изменить, внеся некоторые дополнительные флаги.
При необходимости игнорировать регистр параметра поиска и искать как прописные, так и строчные вариации шаблона, можно использовать утилиты «-i» или «—ignore-case».
Для примера можно использовать grep для поиска в том же файле слова «license», написанного верхним, нижним или смешанным регистром.
grep -i «license» GPL-3 GNU GENERAL PUBLIC LICENSE of this license document, but changing it is not allowed. The GNU General Public License is a free, copyleft license for The licenses for most software and other practical works are designed the GNU General Public License is intended to guarantee your freedom to GNU General Public License for most of our software; it applies also to price. Our General Public Licenses are designed to make sure that you (1) assert copyright on the software, and (2) offer you this License «This License» refers to version 3 of the GNU General Public License. «The Program» refers to any copyrightable work licensed under this . .
Как можно видеть, выведенные результаты содержат «LICENSE», «license», and «License». Если бы в файле был экземпляр «LiCeNsE», он также был бы выведен. При необходимости найти все строки, которые не содержат указанный шаблон, можно использовать флаги «-v» или «—invert-match».
Для примера можно применить следующую команду для поиска в лицензии BSD всех строк, которые не содержат слово «the»:
grep -v «the» BSD All rights reserved. Redistribution and use in source and binary forms, with or without are met: may be used to endorse or promote products derived from this software without specific prior written permission. THIS SOFTWARE IS PROVIDED BY THE REGENTS AND CONTRIBUTORS «AS IS» AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE . .
Как можно видеть, последние две строки были выведены как не содержащие слова «the», поскольку команда «ignore case» не была использована.
Всегда полезно знать номера строк, в которых были обнаружены совпадения. Их можно узнать при помощи флагов «-n» или «—line-number» .
Если применить данный флаг в предыдущем примере, будет выведен следующий результат:
grep -vn «the» BSD 2:All rights reserved. 3: 4:Redistribution and use in source and binary forms, with or without 6:are met: 13: may be used to endorse or promote products derived from this software 14: without specific prior written permission. 15: 16:THIS SOFTWARE IS PROVIDED BY THE REGENTS AND CONTRIBUTORS «AS IS» AND 17:ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE . .
Теперь можно сослаться на номер строки при необходимости внести изменения в каждой строке, которая не содержит «the».
EXAMPLE top
The following example outputs the location and contents of any
line containing “f” and ending in “.c”, within all files in the
current directory whose names contain “g” and end in “.h”. The
-n option outputs line numbers, the -- argument treats expansions
of “*g*.h” starting with “-” as file names not options, and the
empty file /dev/null causes file names to be output even if only
one file name happens to be of the form “*g*.h”.
$ grep -n -- 'f.*\.c$' *g*.h /dev/null
argmatch.h:1:/* definitions and prototypes for argmatch.c
The only line that matches is line 1 of argmatch.h. Note that
the regular expression syntax used in the pattern differs from
the globbing syntax that the shell uses to match file names.








