Как собрать семантическое ядро
Содержание:
Этап 2. Сбор и чистка семантического ядра в Key Collector
Перед началом сбора семантического ядра необходимо указать регион, по которому следует собирать запросы и их частотность. Регион напрямую связан с магазином, для которого собирается семантика, то есть если ваш магазин находится в Москве, то и запросы с их частотностью нужно собирать по данному региону. Для этого в нижней части окна мы выбираем регион для сервисов Yandex.Wordstat и Яндекс Директ:
После выбора региона можно приступать к сбору семантики.
Методика
В основном меню нажимаем кнопку «Пакетный сбор слов из левой колонки Yandex.Wordstat»:
В открывшимся окне мы увидим поле, куда необходимо добавить запросы прямо из нашего файла. После их добавления в нижней правой части окна следует нажать на иконку разделения фраз по группам:
После нажатия на кнопку в правой колонке групп мы увидим, что наши группы добавлены, и во всплывающем окне появилось поле с названиями наших групп, внутри которых находятся соответствующие запросы. Далее мы можем нажимать кнопку «Начать сбор»:
Запустив парсинг левой колонки Yandex.Wordstat, мы автоматически получаем все расширения наших запросов из сервиса, и теперь не будем собирать их вручную.
Следующим шагом является сбор корректной частоты запросов. Для этого следует очистить данные общей частотности, собранной вместе с запросами из сервиса Yandex.Wordstat, нажав на заголовок столбца правой кнопкой мыши и выбрав пункт «Очистить данные в колонке»:
Для сбора частотности мы используем функционал «Сбор статистики Yandex.Direct»:
Во всплывающем окне выбираем период сбора равный году. Это необходимо потому, что спрос на товары зачастую является сезонным, и без годовой частотности мы не сможем выявить самые популярные запросы. Целью сбора выбираем «Базовую» и «Уточненную» частотность, после чего нажимаем кнопку «Получить данные»:
Когда частотность собралась, можно переходить к чистке семантики от мусорных фраз. Мы рекомендуем удалять запросы с «Уточненной» частотностью менее 10, так как это означает, что подобные запросы приносят меньше 1 посетителя в месяц.
Выделяем такие запросы и нажимаем кнопку «Удалить фразы»:
Теперь можно приступить к чистке запросов по фразам.
Для этого есть несколько инструментов:
1. Инструмент фильтрации позволяет быстро отсечь часть ненужных запросов. Используя его, можно оставить в основной таблице только те фразы, которые включают в себя английские символы, цифры или состоят из 4 и более слов и т.п. для пакетного удаления.
2. Инструмент «Стоп-слова» позволяет отмечать фразы на удаление или последующий перенос в другую/новую группу по заранее загруженным в поле словам. Можно сразу выделить запросы с вхождениями городов (отличных от выбранного региона), названий компаний конкурентов, а также информационные запросы со словами «как», «почему», «отзывы», «реферат» и пр.
3. Инструмент «Анализ групп» позволяет собрать запросы в группы по различным вариантам группировки и отмечать названия групп, выделяя сразу несколько запросов для удаления или последующего переноса в другую/новую группу.
Рекомендуем пользоваться всеми инструментами, основным из которых должен стать «Анализ групп». Данный инструмент находится во вкладке «Данные»:
Во всплывающим окне можно увидеть несколько вариантов группировки, из которых мы советуем использовать метод «по отдельным словам».
В данном методе все запросы будут присутствовать в таблице и не случится того, что запрос, не попавший ни в одну группу, будет исключен из таблицы и его придется искать позже вручную в общем списке запросов.
Просматривая группы одну за другой, отмечаем их или фразы внутри них, которые явно нам не подходят. В процессе мы будем наблюдать, что, выбирая пять групп, мы уже отметили в общей таблице 9 фраз:
После того как отметим все группы и запросы в них, мы можем закрыть данное окно и нажать на кнопку «Удалить фразы».
После чего следует перейти к выгрузке запросов в Excel для последующей ручной чистки запросов и группировки семантики.
Чтобы совершить пакетную выгрузку всех запросов из разных групп, необходимо в правой колонке программы отметить все наши группы и нажать кнопку «Режим просмотра мульти-группы». После этого можно выгрузить наше семантическое ядро в Microsoft Excel:
Как собирать ключи
Обзор инструментов для сбора семантики
Список программ и сервисов, которые могут пригодиться на каждом этапе работы с семантическим ядром: сбор ключей, их очистка и кластеризация. Составить исчерпывающий список подходящих продуктов сложно, потому что их достаточно много, так что мы рассмотрели несколько интересных примеров.
В статье собраны сервисы для:
-
Сбора ключевых слов
-
Очистки результатов
-
Группировки ключей
Как собрать ключи для СЯ с помощью Яндекс.Вордстат
Вордстат неточный инструмент, в нем есть не все существующие запросы, а данные несколько искажены, потому что не все пользуются Яндексом. Но этот инструмент подходит для сбора ключей, оценки популярности запросов и прогнозирования.
Расскажем, как комфортно и эффективно пользоваться Яндекс.Вордстатом для сбора ключей: как читать данные, какие операторы помогут искать нужные запросы и какие секреты есть для работы с инструментом.
Поиск длинных запросов в Вордстате
В статье:
-
Зачем нужен Вордстат
-
Работа с операторами Вордстата
-
Как читать данные Wordstat
-
Расширения для Яндекс Вордстата
Как собрать низкочастотные запросы
Собирать запросы только с высокой частотностью неправильно, так вы наверняка попадете в условия огромной конкуренции за топ в поисковой выдаче с тысячами раскрученных сайтов.
Запросы, которые пользователи совершают реже среднечастотных, обычно это не чаще 1000 в месяц, называют низкочастотными. По ним проще выйти в топ, потому что конкуренции меньше. Хоть один такой запрос и дает мало трафика, много низкочастотных уже могут привести какое-то ощутимое количество аудитории.
Рассматриваем, как продвигаться по таким запросам, как их собирать и что с ними делать дальше.
В статье:
-
LT-запросы
-
Суть продвижения по низкочастотным запросам
-
Преимущества продвижения по низкочастотным запросам
-
Как найти и собрать НЧ-запросы
-
Как оптимизировать сайт и отдельную страницу под НЧ
4 тактики подбора ключевых слов, которыми не все пользуются
Адаптированный перевод интересной статьи «Advanced Keyword Research: Four Tactics You’re (Probably) Not Using». Ее автор придумал несколько нестандартных способов собрать ключи, протестировал их, получил результаты, масштабировал и описал результаты в материале. Попробуйте эти способы и вы.
В статье:
-
Подбор ключевиков по молодым сайтам из топа
-
Сбор ключей с помощью пользовательского поиска Google (Google Custom Search Engine)
-
Тактика моделирования запросов, по которым другие сайты попали в топ за несколько недель
-
Реверс-инжиниринг «слабых» сайтов не из топа
Кластеризация запросов
После сбора и чистки семантики необходимо распределить ключевые запросы по страницам. Для этого нужно собрать ТОП выдачи по каждой фразе, после чего найти одинаковые URL. Какой порог кластеризации вы зададите – столько повторяющихся URL должно быть, чтобы ключевые фразы попали в одну группу.
Кластеризация может быть выполнена по трем методам:
- Soft – самый мягкий, используется при низкой конкуренции в тематике. В нем достаточно, чтобы запрос имел общие URL хотя бы с одним ключом из своей группы.
- Middle – более строгий метод, подходит для информационных ресурсов или для коммерческих с невысоким уровнем конкуренции. В нем определяется основной запрос группы, с которым должны быть совпадения по URL у всех остальных.
- Hard – самый строгий метод, используется для коммерческих ресурсов в тематиках с высокой конкуренцией. Все фразы в группе должны иметь друг с другом пересекающиеся URL.
Сервисы, которые помогут кластеризовать поисковые фразы
KeyAssort создан именно для кластеризации запросов. Использует все три метода кластеризации, о которых мы рассказали выше. Инструмент платный, есть демоверсия.
Группировка от Кулакова бесплатный онлайн-кластеризатор. Требует ручной коррекции результата. За один раз можно кластеризовать до 1000 фраз.
Топвизор разработал свой инструмент для группировки. Метод кластеризации можно выбрать самостоятельно. Инструмент платный, есть пробный период.
Rush Analytics также создал свой инструмент для кластеризации семантического ядра. Использует методы Hard и Soft. Тарифные планы начинаются от 500 руб.
Overlid инструмент для полноценной работы с семантическим ядром. Проводит кластеризацию на основе более чем 20 факторов. Обработка одной поисковой фразы стоит от 19 коп.
Pixel Tools предлагает четыре метода кластеризации. Три из них стандартные, а четвертый уникальный метод компании. Функция кластеризации доступна на платном аккаунте, стоимость тарифа от 950 руб. в месяц.
Arsenkin предлагает два метода кластеризации: Soft и Hard. Глубину проверки можно увеличить до ТОП-30. Инструмент доступен на платном аккаунте, стоимость тарифа от 549 руб. в месяц.
JustMagic использует только метод Hard-кластеризации. Есть бесплатная часть, но, чтобы получить полный функционал, необходимо купить подписку от 999 руб. в месяц.
После автоматической кластеризации семантического ядра обязательно вручную проверьте полученную структуру и ключевые запросы. Одиночные фразы, которые не вошли ни в одну группу, имеет смысл отложить или расширить, чтобы на страницу вело несколько ключевых слов.
Платные инструменты для составления семантического ядра:
Базы Пастухова по мнению многих специалистов не имеют конкурентов. В базе отображаются такие запросы, которые не показывает ни Гугл, ни Яндекс. Существует много других особенностей, присущих именно базам Макса Пастухова, среди которых можно отметить удобную программную оболочку.
SpyWords — интересный инструмент, позволяющий анализировать ключевые слова конкурентов. С его помощью можно провести сравнительный анализ семантических ядер интересующих ресурсов, а также получить все данные о РРС и SEO компаниях конкурентов. Ресурс русскоязычный, разобраться с его функционалом не составит никаких проблем.
Key Collector — платная программа, созданная специально для профессионалов. Помогает составлять семантическое ядро, определяя актуальные запросы. Используется для оценки стоимости продвижения ресурса по интересующим ключевым словам. Помимо высокого уровня эффективности, данная программа выгодно отличается удобством в использовании.
SEMrush позволяет на основании данных с конкурирующих ресурсов определить наиболее результативные ключевые слова. С его помощью можно подобрать низкочастотные запросы, характеризующиеся высоким уровнем трафика. Как показывает практика, по таким запросам очень легко продвинуть ресурс на первые позиции выдачи.
SeoLib — сервис, завоевавший доверие со стороны оптимизаторов. Обладает достаточно большим функционалом. Позволяет грамотно составить семантическое ядро, а также выполнить необходимые аналитические мероприятия. В бесплатном режиме можно проанализировать 25 запросов в сутки.
Prodvigator позволяет собрать первичное семантическое ядро буквально за несколько минут. Это сервис используемый главным образом для анализа конкурирующих сайтов, а также для подбора наиболее результативных ключевых запросов. Анализ слов выбирается для Google по России или для Яндекса по Московскому региону.
Семантическое ядро собирается достаточно быстро, если использовать источники и базы данных в качестве подсказки.
Следует выделить следующие процессы
— Согласно содержанию сайта и релевантных тем выбираются ключевые запросы, которые наиболее точно отражают смысловую нагрузку вашего веб-портала.
— Из выбранного набора отсеиваются лишние, возможно, те запросы, которые могут ухудшить индексацию ресурса. Фильтрация ключевых слов проводится на основании результатов анализа, описанного выше.
— Полученное семантическое ядро должно быть равномерно распределено между страницами сайта, при необходимости заказываются тексты с определенной тематикой и объемом вхождения ключевых слов.
Может пригодиться: продвижение объекта недвижимости — действительно достойные результаты от Семантики
Этапы работы с семантическим ядром
Теперь когда мы знаем, что такое семядро и для чего оно нужно, а также знакомы с основными классификациями запросов, давайте вкратце разберём основные этапы работы с ядром.
Сбор семантики
Подробные способы сбора семантики будут даны в части «», здесь же мы остановимся на основных моментах.
На этом этапе вы должны найти и выписать общие запросы (их ещё называют маркерными), которые характеризуют деятельность вашего бизнеса: как общие направления, так и отдельные услуги и товары.
Например, вы продаёте мотоциклы определённой компании. Вашими маркерными запросами могут являться «мотоциклы», «мотоциклы + бренд» , «как выбрать мотоцикл», «запчасти для мотоцикла + бренд», «как ухаживать за мотоциклом», «классические/спортивные/круизёры и другие типы мотоциклов», «ремонт мотоциклов + бренд» и т.д. То есть в зависимости от оказываемых услуг или имеющихся товаров выбираются соответствующие маркеры.
После определения маркерных запросов проверяйте собранные ключевые слова в основных сервисах статистики запросов: Яндекс.Вордстат или Google Ads Планировщик ключевых слов. В них вы найдёте как частотность запросов, так и варианты других ключевых слов по вашей тематике. Собирайте всё, что как-то связано с вашим бизнесом.
Принципиальная разница между обозначенными сервисами заключается в следующем:
- Статистика в каждом актуальна только для родной поисковой системы. То есть если запрос «юридические услуги» смотреть в Вордстате, то показов будет более 100 000 именно в Яндекс. В Планировщике ключевых слов значения соответственно будут отличаться в Google.
- Плюс Вордстата в том, что он показывает точное значение показов запроса. Если у вас новый аккаунт в Google Ads, вместо точных значений запроса вы получите диапазоны типа 10–100, 100–1000 и т.д.
- Плюс Планировщика ключевых слов в том, что он даёт множество вариантов ключей сразу, чтобы учесть все варианты запросов для вашего сайта в продвижении и рекламе.
Если денег на платные инструменты нет, советуем использовать сразу 2 сервиса при сборе семантики. Но всё же рекомендуем купить Key Collector. Его основная задача — это автоматический сбор (парсинг) ключевых слов не только с Вордстата и Планировщика, но и с других сервисов и баз. Это не реклама данного инструмента, но уточним, что, кроме парсинга, сервис удобен для чистки и кластеризации ядра. Для многих SEO-специалистов Key Collector как швейцарский нож.
Интерфейс KeyCollector
Очистка
Когда все варианты запросов пользователей собраны в одной таблице, наступает время чистки от лишнего.
Лишними являются запросы, которые:
- слишком общие,
- не относятся к деятельности вашего сайта,
- не подходят по географии,
- включают в себя неактуальные цифры и даты,
- имеют брендовые составляющие конкурентов,
- состоят из 8 слов и более,
- затруднительно использовать на одной странице.
В качестве примера приведём подобранные ключи для одной из компаний, которая занимается продажей электрических каминов в Санкт-Петербурге:
Кластеризация и выбор страниц
Кластеризация — это группировка запросов по общности их смысловых значений в иерархическом порядке. То есть в одном кластере, или группе, должны быть запросы, описывающие одну сущность в глазах пользователя и поисковой системы. Делается это либо вручную, либо с помощью специальных сервисов.
Вернёмся к нашим каминам и возьмём следующие запросы:
- камин электрический с эффектом пламени;
- камины электрические с эффектом живого пламени;
- камины электрические фото;
- купить камин электрический;
- камин электрический купить в спб;
- угловой камин электрический;
- угловые камины электрические купить.
Первые два запроса можно объединить в один кластер и продвигать на одной странице. 3-й предполагает галерею или каталог, 4 и 5-й маркерные и достаточно общие, поэтому для них подойдёт главная страница или каталог. 6 и 7-й описывают категорию электрокаминов и под них стоит создать отдельную страницу на сайте.
Это пример ручной кластеризации, но мы указали, что запросы должны описывать одну сущность и в глазах пользователя, и поисковика. И вот тут начинаются проблемы, потому что часто можно столкнуться с тем, что схожие на первый взгляд запросы формируют разную поисковую выдачу. Чтобы избежать таких ошибок, используются специальные сервисы кластеризации, которые сравнивают выдачу и группируют кластеры.
Мониторинг
Важно не просто собрать ключевые слова и использовать их в создании контента для сайта, но и отслеживать рост позиций и трафика по этим запросам. О том, как это делать и какие сервисы можно использовать, читайте в нашей статье про проверку позиций
Что такое семантическое ядро простыми словами
Как это ни странно, но семантическое ядро – это обычный excel файл, в котором списком представлены ключевые запросы, по которым вы (или ваш копирайтер) будете писать статьи для сайта.
Вот как, например, выглядит мое семантическое ядро:
Зеленым цветом у меня помечены те ключевые запросы, по которым я уже написал статьи. Желтым – те, которым статьи собираюсь написать в ближайшее время. А бесцветные ячейки – это значит, что до этих запросов дело дойдет немного позже.
Для каждого ключевого запроса у меня определена частотность, конкурентность, и придуман “цепляющий” заголовок. Вот примерно такой же файл должен получиться и у вас. Сейчас у меня СЯ состоит из 150 ключевиков. Это значит, что я обеспечен “материалом” минимум на 5 месяцев вперед (если даже буду писать по одной статье в день).
Чуть ниже мы поговорим о том, к чему вам готовиться, если вы вдруг решите заказать сбор семантического ядра у специалистов. Здесь скажу кратко – вам дадут такой же список, но только на тысячи “ключей”
Однако, в СЯ важно не количество, а качество. И мы с вами будем ориентироваться именно на это
Зачем вообще нужно семантическое ядро?
А в самом деле, зачем нам эти мучения? Можно же, в конце концов, просто так писать качественные статьи, и привлекать этим аудиторию, правильно? Да, писать можно, а вот привлекать не получится.
Главная ошибка 90% блогеров – это как раз написание просто качественных статей. Я не шучу, у них реально интересные и полезные материалы. Вот только поисковые системы об этом не знают. Они же не экстрасенсы, а всего лишь роботы. Соответственно они и не ставят вашу статью в ТОП.
Здесь есть еще один тонкий момент с заголовком. Например, у вас есть очень качественная статья на тему “Как правильно вести бизнес в “мордокниге”. Там вы очень подробно и профессионально расписываете все про фейсбук. В том числе и то, как там продвигать сообщества. Ваша статья – самая качественная, полезная и интересная в интернете на эту тему. Никто и рядом с вами не валялся. Но вам это все равно не поможет.
Почему качественные статьи вылетают из ТОПа
Представьте, что на ваш сайт зашел не робот, а живой проверяльщик (асессор) с Яндекса. Он понял, что у вас самая классная статья. И рукам поставил вас на первое место в выдаче по запросу “Продвижение сообщества в фейсбук”.
Знаете, что произойдет дальше? Вы оттуда все равно очень скоро вылетите. Потому что по вашей статье, даже на первом месте, никто не будет кликать. Люди вводят запрос “Продвижение сообщества в фейсбук”, а у вас заголовок – “Как правильно вести бизнес в “мордокниге”. Оригинально, свежо, забавно, но… не под запрос. Люди хотят видеть именно то, что они искали, а не ваш креатив.
Соответственно, ваша статья будет вхолостую занимать место в ТОП выдачи. И живой асессор, горячий поклонник вашего творчества, может сколько угодно умолять начальство оставить вас хотя бы в ТОП-10. Но не поможет. Все первые места займут пустые, как шелуха от семечек, статейки, которые друг у друга переписали вчерашние школьники.
Зато у этих статей будет правильный “релевантный” заголовок – “Продвижение сообщества в фейсбук с нуля” (по шагам, за 5 шагов, от А до Я, бесплатно и пр.) Обидно? Еще бы. Ну так боритесь против несправедливости. Давайте составим грамотное семантическое ядро, чтобы ваши статьи занимали заслуженные первые места.
Еще одна причина начать составлять СЯ прямо сейчас
Есть еще одна вещь, о которой почему-то люди мало задумываются. Вам надо писать статьи часто – как минимум каждую неделю, а лучше 2-3 раза в неделю, чтобы набрать побольше трафика и побыстрее.
Все это знают, но почти никто этого не делает. А все потому, что у них “творческий застой”, “никак не могут себя заставить”, “просто лень”. А на самом деле вся проблема именно в отсутствие конкретного семантического ядра.
Наше СЯ – это как контент-план для социальных сетей. То есть там написано конкретно, что мы будем делать в ближайшие 2-3 месяца. Нам не надо будет садиться с утра и начать выдумывать тему для нового поста. У нас все придумано, продумано и прочитано.
Именно это и спасет вас от так называемого “творческого кризиса”. Когда вы точно знаете, что вам делать – становится гораздо легче. Поэтому ни в коем случае не пропускайте этап создания семантического ядра (каким бы муторным вам это дело не показалось). Потом вам все равно придется подбирать темы и запросы, но только потратите вы на это в десять раз больше времени и сил.
А теперь. собственно, давайте разберем, как правильно составить семантическое ядро с нуля.
Следующие шаги после сбора семантики
Готовый список ключей насчитывает в себе сотни и даже тысячи строк с разными словами. Поэтому его нужно почистить – убрать лишний «шум», а после разложить по тематическим группам (кластеризовать). Хороший пример, как это реализовано, можно посмотреть на ресурсе Автопортал 100.ks.ua.
Под чисткой списка запросов подразумевается удаление неполных ключей или неподходящих под нишу запросов. Для этой задачи также подходит любой платный софт, который автоматически их вычислит и уберет.
Кластеризация ключей
Распределение по группам (кластеризацию) можно сделать вручную или через программу. Первый способ подходит, если ключей немного, здесь используем таблицы Excel/Google. В другом случае – лучше доверить процесс работе платных программ. Например, Rush Analytics, SpyWords, KeyClusterer, Key collector и др.
Оба варианта не идеальны. Ручной способ занимает слишком много времени, к тому же, есть риск ошибки. А в автоматизированной программе захватываются пересечения конкурентов, иногда они могут абсолютно не совпадать с нужным вам запросом.
Способы составления семантического ядра
Key Collector
Для составления семантики мы можем воспользоваться программами для создания СЯ. Какие-то из них делают почти всю работу за вас – их еще называют автоматическими. В каких-то сервисах придется больше работать самостоятельно.
Например, есть такая платная утилита Key Collector. Хотя в ней этот процесс почти полностью автоматизирован, необходимо знать, как настроить Key Collector. На выходе вам лишь остается немного прибраться в запросах, убрав оттуда наиболее бесполезные, что включает в себя запросы от роботов, спам и т. д. Стоимость такой программы составляет почти 2 000 рублей.
Яндекс Вордстат
Заниматься сбором семантики можно и с помощью сервиса от Яндекса – Вордстат. Им очень легко пользоваться, достаточно просто ввести ключевое слово, он выведет вам запросы, в которых присутствует данный ключ. Вместе с этим Wordstat покажет вам и похожие запросы, которые также могут быть интересны при продвижении.
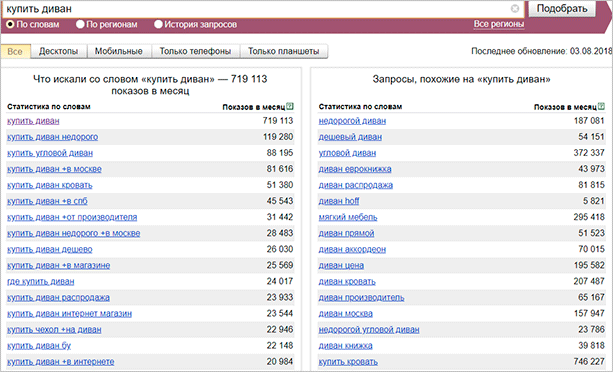
В этой статье с помощью Вордстата мы будем собирать первичные ключи, которые понадобятся нам для дальнейшего сбора семантического ядра. Но об этом позже, а пока я приведу вам еще несколько способов, с помощью которых можно собрать семантику.
Яндекс Вордстат + СловоЁБ
Программа с таким красочным названием является абсолютно бесплатным аналогом Key Collector. Естественно и функционала в нем чуть меньше, чем в коммерческом конкуренте, но для сбора семантического ядра под поисковое продвижение этого вполне хватит.
Если вам интересно, чем СловоЁБ отличается от Кей Коллектора, просто взгляните на эту табличку.
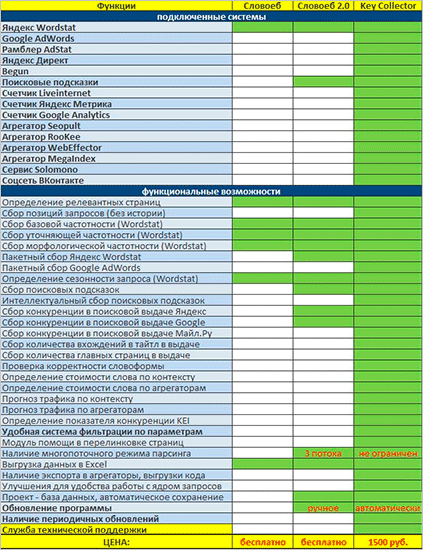
Безусловно, отличий здесь вагон и маленькая тележка. Однако для простого сбора ядра возможностей СловоЁБа вполне хватит.
Онлайн-сервисы
Итак, помимо вышеописанных вариантов, семантику можно сделать с помощью онлайн-сервисов. Если вы забьете запрос “Сбор семантики онлайн”, то поисковик выдаст вам большое количество всевозможных онлайн-инструментов. Они могут быть как хорошими, так и плохими. И, соответственно, как платными, так и бесплатными.
С помощью различных онлайн-сервисов можно еще узнать семантическое ядро конкурентов. Будьте уверены, что практически все компании занимаются проверкой данных своих потенциальных соперников.
Заказ у специалиста
Вы можете просто купить готовое решение у специалиста. Он все сделает, и на выходе вы получите целостный файлик со всеми запросами. Далее из него уже можно будет создать список статей с техническими заданиями к ним. Ну и отдать это все на растерзание копирайтерам. Но это уже вопрос делегирования обязанностей, его сегодня затрагивать мы не будем.
Keywordtool
Сервис собирает семантику для зарубежных сайтов в широком соответствии. Отдельно можно подбирать поисковые подсказки и фразы, в которые включено базовое ключевое слово. В одной сессии бесплатной версии сервис отдает до 1000 фраз без указания частотности.
Достоинства:
- широкая география подбора запросов и выбор языка;
- отдает поисковые запросы из YouTube, Amazon, eBay, App Store;
- охват поисковых запросов больше, чем у Google Рекламы;
- удобное копирование списка запросов — можно перенести в любую таблицу в один клик.
Недостатки:
- не показывает частотность в бесплатной версии;
- нельзя загружать фразы для поиска списком;
- не ищет синонимы ключевого слова, а только фразы, в которые оно включено.








