Субд
Содержание:
- Технология работы с СУБД Access
- § 1. Понятие базы данных. Система управления базами данных (СУБД)
- Список литературы по теме:
- 2 Построение концептуальной модели
- Мультимодельные СУБД на основе реляционной модели
- InnoDB
- Каким требованиям должна отвечать современная СУБД?
- Иерархическая база данных
- Сравниваем три модели баз данных
- MEMORY (HEAP)
- Отношения и типы данных
- Логическое проектирование и оптимизация
- BDB (BerkeleyDB)
- Формы
- О языке SQL
- MyISAM
- Отчеты
- MongoDB
- Проектирование баз данных
- MySQL
Технология работы с СУБД Access
Разработка СУБД в Access выполняется при помощи следующих пунктов:
-
Определить цель разработки базы данных. Необходимо определить назначение, узнать, в каком направлении двигаться — как предполагают использовать базу данных, какие результаты хотят получить, какие функции должны быть реализованы.
-
Определить примерное количество таблиц в базе данных — информацию необходимо систематизировать и “разложить все по полочкам”. Не следует добавлять слишком много полей в одну таблицу: лучше распределить данные на две и связать их. Каждая таблица должна содержать только одну тему.
-
Определить все поля и их типы данных в таблицах. Данные в ячейках должны соответствовать типам, чтобы в дальнейшем не возникло проблем с вычислениями, группировкой и сортировкой.
-
Определить соотношения таблицы-поля.
-
Обозначить первичные и (при необходимости) вторичные ключи в таблицах.
-
Построить схему данных для БД, отражающую связи между таблицами. Максимизировать взаимодействие между данными при помощи этих связей.
-
Усовершенствовать структуру, наглядно посмотрев на всю имеющуюся информацию и ее возможную систематизацию.
-
Воспользоваться анализом самого Access для очередной проверки.
Создание СУБД в Access возможно двумя способами:
-
использовать мастера БД для создания необходимых объектов;
-
создать пустую БД, дополняя ее новыми объектами самостоятельно.
MS Access позволяет расширить базу данных уже после ее создания, но основную структуру необходимо продумать заранее: такие вещи, как типы данных, впоследствии, особенно после заполнения таблицы, поменять будет невозможно.
Продуманную схему данных можно реализовать при помощи соответствующей вкладки в СУБД. Каждый из видов связи наглядно показывается в Access. Связи можно видоизменять или даже удалять.
§ 1. Понятие базы данных. Система управления базами данных (СУБД)
◄ Предыдущая: 1.1. Базы данных. Поле. Запись Следующая: Вопросы к параграфу ►
1.2. Назначение системы управления базами данных
Система управления базами данных (СУБД) — программный комплекс, предназначенный для создания, редактирования и совместного использования баз данных.
По степени локализации программных компонентов СУБД разделяют на:
1. Локальные — все программы размещаются на одном компьютере.
2. Распределенные — часть программ размещается на сервере, другая часть — на клиентских компьютерах.
Рассмотрите
Распределенные СУБД позволяют многим пользователям работать с одной базой данных одновременно.
Основные действия, которые пользователь может выполнить с помощью СУБД:
создание структуры БД;
заполнение БД информацией;
редактирование структуры и содержания БД;
поиск информации в БД;
сортировка данных.
Работу с реляционными базами данных рассмотрим в СУБД Access С пользовательским интерфейсом СУБД Access можно познакомиться в Приложении к главе 1.
Для создания новой базы данных в Access требуется выполнить следующие действия:
1. На стартовой странице выбрать Пустая база данных… (см. Приложение к главе 1).
2. В открывшемся окне в поле Имя файла ввести имя файла, выбрать значок папки, чтобы определить место хранения файла базы данных.
3. Создать и сохранить базу данных, нажав на кнопку Создать.
Рассмотрите
Файлы баз данных, созданных в Access, имеют расширение .accdb. Один файл базы данных может содержать не только несколько объектов Таблица, но и различное количество объектов Форма, Запрос и Отчет. Список объектов базы данных отображается в Области навигации
Открыть объекты базы данных можно разными способами:
1. Выполнить двойной щелчок по объекту в Области навигации.
2. Выбрать режим открытия из контекстного меню вкладки объекта.
Для закрытия объекта/объектов базы данных нужно выбрать соответствующую команду контекстного меню вкладки открытого объекта .
Пример 1.2. Реляционные СУБД.
1. Локальные.
2. Распределенные.
В базах данных зачастую хранится очень важная информация, например финансовая
Поэтому при работе с базами данных важно обеспечить целостность данных, т. е
защитить их от потерь в случае отказа оборудования (например, при отключении питания).
Целостность данных в СУБД обеспечивается за счет механизма транзакций.
Транзакция — группа операций, необходимых для совершения законченного логического действия. Транзакция должна быть выполнена полностью или не выполнена вообще.
Пример 1.3. Логотипы СУБД Access различных версий.
Пример 1.4. Создание базы данных в Access.
Пример 1.5. Область навигации базы данных в Access.
Пример 1.6. Контекстное меню вкладки открытой таблицы базы данных.
Список литературы по теме:
- Когаловский М.Р. Энциклопедия технологий баз данных. — М.: Финансы и статистика, 2002. — 800 с.
- Кузнецов С. Д. Основы баз данных. — 2-е изд. — М.: Интернет-университет информационных технологий; БИНОМ. Лаборатория знаний, 2007. — 484 с. Дейт К. Дж. Введение в системы баз данных = Introduction to Database Systems. — 8-е изд. — М.: Вильямс, 2005. — 1328 с. Коннолли Т., Бегг К. Базы данных. Проектирование, реализация и сопровождение. Теория и практика = Database Systems: A Practical Approach to Design, Implementation, and Management. — 3-е изд. — М.: Вильямс, 2003. — 1436 с.
- Гарсиа-Молина Г., Ульман Дж., Уидом Дж. Системы баз данных. Полный курс = Database Systems: The Complete Book. — Вильямс, 2003. — 1088 с. C. J. Date Date on Database: Writings 2000–2006. — Apress, 2006. — 566 с.
Файловая система NTFS Что такое информация?
2 Построение концептуальной модели
Выше были отображены основные сущности, но не отображены роли пользователей, хотя их тоже должна хранить система. Они показаны ниже на ER-диаграмме в нотации Чена .
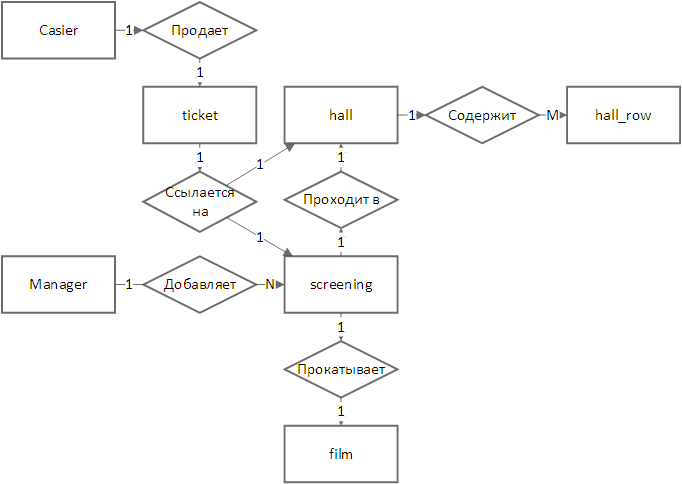
На диаграмме выделены роли кассира и менеджера, а также основные отношения между сущностями. На диаграмме нет роли администратора, но его роль заключается в:
- создании всех таблиц базы;
- добавлении залов и рядов в них;
- добавлении кассиров и менеджеров.
На диаграмме не отражена роль посетителя, так как:
- билет не содержит информации о том, кто его купил (посетитель может подарить билет другу);
- система вообще не хранит информацию о посетителях;
- покупку билета он осуществляет через общение с кассиром вне системы;
- никакие данные в базе посетитель самостоятельно изменить не может.
На диаграмме проставлены кратности связей, например, видно, что один менеджер может добавить много (N) прокатов. В этой базе не оказалось связей типа N:M, сложных или рекурсивных связей — такие связи являются препятствиями в проектировании и решаются изменением ее структуры.
Для формирования схемы данных необходимо сначала дополнить ER-диаграмму реквизитами сущностей (уточнить ее) — результат приведен на рисунке.
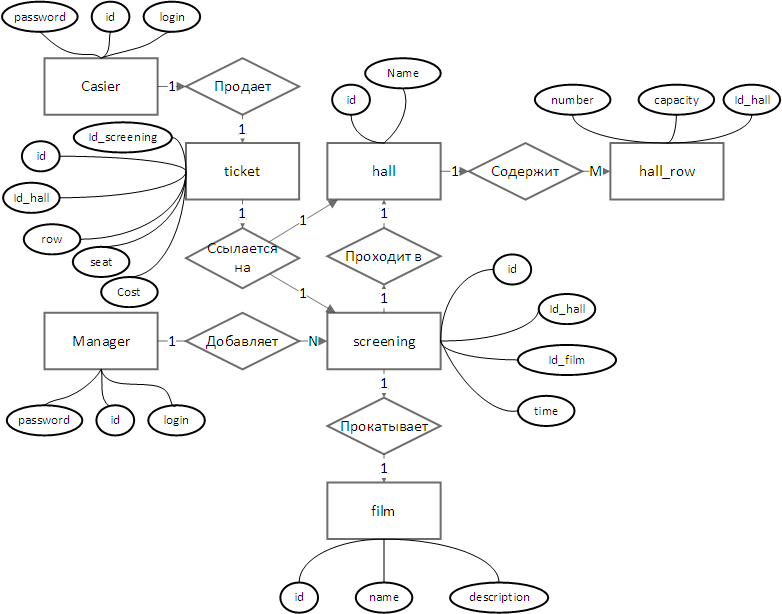
- система не должна позволять продавать несколько билетов на одно и то же место при одном показе фильма. Это значит, что вторичным ключем для Билета должен быть кортеж (id_screening, row, seat). Однако, тогда нет необходимости в id билета — на билеты не ссылается ни одна таблица, это поле может быть удалено. Изначально id был добавлен потому, что обычно на билетах в кинотеатрах печатается номер;
- билет хранит поле id_hall, это было сделано для того, чтобы посетитель кинотеатра мог найти свой кинозал. Однако, билет, выдаваемый пользователю — это не тоже самое, что информация о билетах, хранимая в базе данных. Билет базы данных хранит также поле id_screening, а Показ уже ссылается на id_hall. Таким образом, в базе нет смысла хранить id_hall в таблице билетов.
Исправленная ER-диаграмма приведена ниже:
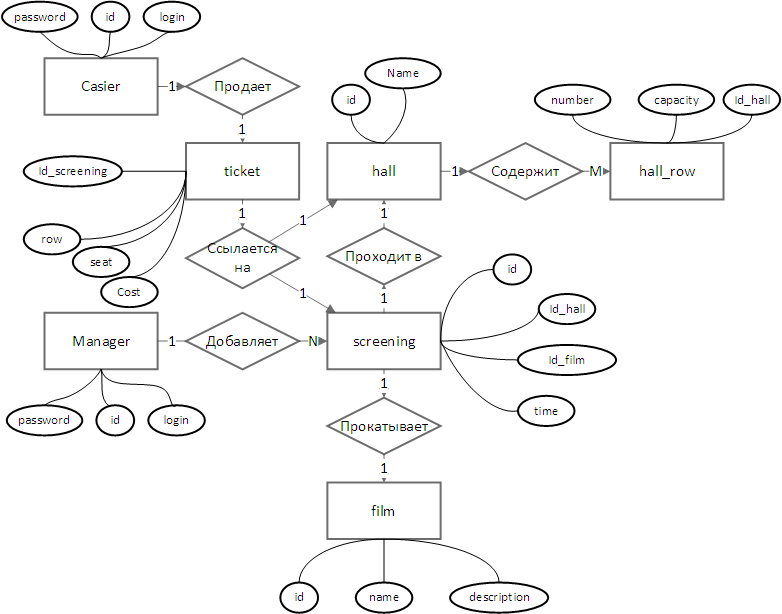
Таблица менеджеров и кассиров не объединены в таблицу Users так как вопросы разграничения прав доступа в различных СУБД решаются по-разному. Так, в MS SQL пользователи добавляются с помощью специальных запросов типа:
при этом вообще нет необходимости хранить информацию об их логинах и паролях в таблицах. Однако, вопросы разграничения доступа решаются позже — на этапе физического проектирования.
Мультимодельные СУБД на основе реляционной модели
Ведущими СУБД в настоящее время являются реляционные, прогноз Gartner нельзя было бы считать сбывшимся, если бы РСУБД не демонстрировали движения в направлении мультимодельности. И они демонстрируют. Теперь соображения о том, что мультимодельная СУБД подобна швейцарскому ножу, которым ничего нельзя сделать хорошо, можно направлять сразу Ларри Эллисону.
Автору, однако, больше нравится реализация мультимодельности в Microsoft SQL Server, на примере которого поддержка РСУБД документной и графовой моделей и будет описана.
Документная модель в MS SQL Server
О том, как в MS SQL Server реализована поддержка документной модели, на Хабре уже было две отличных статьи, ограничусь кратким пересказом и комментарием:
- Работаем с JSON в SQL Server 2016
- SQL Server 2017 JSON
Способ поддержки документной модели в MS SQL Server достаточно типичен для реляционных СУБД: JSON-документы предлагается хранить в обычных текстовых полях. Поддержка документной модели заключается в предоставлении специальных операторов для разбора этого JSON:
- для извлечения скалярных значений атрибутов,
- для извлечения поддокументов.
Вторым аргументом обоих операторов является выражение в JSONPath-подобном синтаксисе.
Абстрактно можно сказать, что хранимые таким образом документы не являются в реляционной СУБД «сущностями первого класса», в отличие от кортежей. Конкретно в MS SQL Server в настоящее время отсутствуют индексы по полям JSON-документов, что делает затруднительными операции соединения таблиц по значениям этих полей и даже выборку документов по этим значениям. Впрочем, возможно создать по такому полю вычислимый столбец и индекс по нему.
Дополнительно MS SQL Server предоставляет возможность удобно конструировать JSON-документ из содержимого таблиц с помощью оператора — возможность, в известном смысле противоположную предыдущей, обычному хранению. Понятно, что какой бы быстрой ни была РСУБД, такой подход противоречит идеологии документных СУБД, по сути хранящих готовые ответы на популярные запросы, и может решать лишь проблемы удобства разработки, но не быстродействия.
Наконец, MS SQL Server позволяет решать задачу, обратную конструированию документа: можно разложить JSON по таблицам с помощью . Если документ не совсем плоский, потребуется использовать .
Графовая модель в MS SQL Server
Поддержка графовой (LPG) модели реализована в Microsoft SQL Server тоже вполне предсказуемо: предлагается использовать специальные таблицы для хранения узлов и для хранения ребер графа. Такие таблицы создаются с использованием выражений и соответственно.
Таблицы первого вида сходны с обычными таблицами для хранения записей с тем лишь внешним отличием, что в таблице присутствует системное поле — уникальный в пределах базы данных идентификатор узла графа.
Аналогично, таблицы второго вида имеют системные поля и , записи в таких таблицах понятным образом задают связи между узлами. Для хранения связей каждого вида используется отдельная таблица.
Проиллюстрируем сказанное примером. Пусть графовые данные имеют схему как на приведенном рисунке. Тогда для создания соответствующей структуры в базе данных нужно выполнить следующие DDL-запросы:
Основная специфика таких таблиц заключается в том, что в запросах к ним возможно использовать графовые паттерны с Cypher-подобным синтаксисом (впрочем, «» и пр. пока не поддерживаются). Также на основе измерений производительности можно предположить, что способ хранения данных в этих таблицах отличен от механизма хранения данных в обычных таблицах и оптимизирован для выполнения подобных графовых запросов.
Более того, довольно трудно при работе с такими таблицами эти графовые паттерны не использовать, поскольку в обычных SQL-запросах для решения аналогичных задач потребуется предпринимать дополнительные усилия для получения системных «графовых» идентификаторов узлов (, , ; по этой же причине запросы на вставку данных не приведены здесь как слишком громоздкие).
Подводя итог описанию реализаций документной и графовой моделей в MS SQL Server, я бы отметил, что подобные реализации одной модели поверх другой не кажутся удачными в первую очередь с точки зрения языкового дизайна. Требуется расширять один язык другим, языки не вполне «ортогональны», правила сочетаемости могут быть довольно причудливы.
InnoDB
Данный тип таблиц обеспечивает высокую производительность и устойчивое хранение данных в таблицах объемом вплоть до 1 Тбайт и нагрузкой на
сервер до 800 вставок/обновлений в секунду.Особенности таблиц типа InnoDB:
- Таблицы не создаются в базах данных, и для каждой из таблиц не выделяется отдельный файл данных. Исключение – файл определения с расширением frm, который создается по умолчанию. Все таблицы хранятся в едином табличном пространстве, поэтому имена таблиц должны быть уникальными.
- Хранение данных в едином табличном пространстве позволяет снять ограничение на объем таблиц, так как файл с таблицами может быть разбит не несколько частей и распределен по нескольким дискам или даже хостам.
- Данный тип таблиц поддерживает автоматическое восстановление после сбоев.
- Обеспечивается поддержка транзакций.
- Единственный тип таблиц, поддерживающий внешние ключи и каскадное удаление.
- Выполняется блокировка на уровне отдельных записей.
- Расширенная поддержка кодировок.
- Рушатся при достижении объема в несколько гигабайт, однако заметно уступают в скорости и не поддерживают полнотекстовый поиск.
Каким требованиям должна отвечать современная СУБД?
Информационное хранилище должно постоянно пополняться новыми данными в соответствии с ритмом жизни компании, это же касается и формирование новых категорий учета.
При этом вносить информацию должен иметь возможность любой новый сотрудник. То же касается и обслуживания данной инфраструктуры со стороны системного администратора, формирования новых выборок данных со стороны аналитиков с разным уровнем допуска к информации и с разными профилями анализируемых данных.
Необходимо отметить, что количество информации увеличивается не только в объеме, но и качественно. В результате появляется необходимость одновременной работы с ней нескольких экспертов. Кроме того, появляется возможность привлечения специализированных экспертов для выполнения сложных процедур анализа данных (Data mining Интеллектуальный анализ данных). Сегодня не только для формирования будущей стратегии, но и для выполнения повседневных задач все большее значение имеет прогнозная аналитика, которая для формирования верного вектора развития использует объективные, а не субъективные данные.
Помимо этого единая база данных упрощает формирования отчетности как отдельным подразделениям компании, так и всей компании в целом для подачи документов в государственные инстанции или их предоставления для ознакомления внешним экспертным комиссиям. Единая база позволяет в автоматическом режиме обновлять документацию, относящуюся к нормативно-справочной информации (НСИ). Дополнительно общая база данных позволяет оперировать информацией в своеобразной унифицированной форме, делая процедуры анализа информации более единообразными в рамках компании.
Еще одним плюсом от единого подхода к хранению информации является гораздо более простая процедура резервирования, снижение времени простоя после сбоя, обеспечение безопасности данных в плане распределения прав доступа, более прозрачная процедура миграции на новые версии программного и аппаратного обеспечения.
Иерархическая база данных
Под иерархической понимается такая база данных, в которой хранение данных и их структурирование осуществляется по принципу разделения элементов на родительские и дочерние. Преимуществом таких баз является лёгкость в чтении запрашиваемой информации и её быстрое предоставление пользователю.
Компьютер способен быстро ориентироваться в ней. Иерархический принцип взят за основу в структурировании файлов и папок в операционной системе Windows, а реестр хранит информацию о параметрах работы тех или иных приложений в структурированном иерархическим способом виде.
Все интернет-ресурсы также построены по иерархическому принципу, так как при его использовании ориентироваться в рамках сайта очень легко.
В качестве примера можно привести базу данных на языке XML, содержащую в себе очерки о состоянии сельского хозяйства в регионах России. В этом случае родительским элементом выступит государство, далее пойдёт разделение на субъекты, а в рамках субъектов будет своё разветвление. В данном случае от верхнего элемента к нижнему идёт строго одно обращение.
Сравниваем три модели баз данных
Первая, иерархическая модель данных, имеет древовидную структуру («родитель-потомок»), и поддерживает только отношения типа «один к одному» или «один ко многим». Эта модель позволяет быстро получать данные, но не отличается гибкостью. Иногда роль элемента (родителя или потомка) неясна и не подходит для иерархической модели.
Вторая, сетевая модель данных, имеет более гибкую структуру, чем иерархическая модель данных, и поддерживает отношения «многие ко многим». Но быстро становится слишком сложной и неудобной для управления.
Третья модель — реляционная — более гибкая, чем иерархическая и проще для управления, чем сетевая. Реляционная модель сегодня используется чаще всего.
Объект в реляционной модели баз данных определяется как позиция информации, хранимой в базе данных. Объект может быть осязаемым или неосязаемым. Примером осязаемого объекта может быть сотрудник организации, а примером неосязаемой сущности — учётная запись покупателя. Объекты определяются атрибутами — информационным отображением свойств объекта. Эти атрибуты также известны как столбцы, а группа столбцов — как ряд. Ряд также можно определить как экземпляр объекта.
Объекты связываются отношениями, основные типы которых можно определить следующим образом:
«Один к одному»
В этом виде отношений один объект связан с другим. Например, Менеджер -> Отдел.
У каждого менеджера может быть только один отдел, и наоборот.
«Один ко многим»
В моделях данных отношение одного объекта с несколькими. Например, Сотрудник -> Отдел.
Каждый сотрудник может быть только в одном отделе, но в самом отделе может быть больше одного сотрудника.
«Многие ко многим»
В заданный момент времени объект может быть связан с любым другим. Например, Сотрудник -> Проект.
Сотрудник может участвовать в нескольких проектах, и каждый проект может объединять несколько сотрудников.
В реляционной модели объекты и их отношения представлены двухмерным массивом или таблицей.
Каждая таблица представляет объект.
Каждая таблица состоит из рядов и столбцов.
Отношения между объектами представлены столбцами.
Каждый столбец представляет атрибут объекта.
Значения столбцов выбираются из области или набора всех возможных значений.
Столбцы, которые используются для связи объектов, называются ключевыми. Есть два типа ключей — первичные и внешние.
Первичные служат для однозначного определения объекта. Внешний ключ — это первичный ключ одного объекта, существующий как атрибут в другой таблице.
Преимущества реляционной модели данных:
- Простота использования.
- Гибкость.
- Независимость данных.
- Безопасность.
- Простота практического применения.
- Слияние данных.
- Целостность данных.
Недостатки:
- Избыточность данных.
- Низкая производительность.
MEMORY (HEAP)
Тип таблиц MEMORY хранится в оперативной памяти, поэтому все запросы к такой таблице выполняются очень быстро. Недостатком является полная потеря данных в случае сбоя работы сервера, поэтому в таблице данного типа хранят только временную информацию, которую можно легко восстановить заново.
При создании таблицы типа MEMORY она ассоциируется с одним-единственным файлом, имеющим расширение frm, в котором определяется структура таблицы.
При остановке или перезапуске сервера данный файл остается в текущей азе данных, но содержимое таблицы, которое хранится в оперативной памяти, теряется.
Ограничения MEMORY таблиц:
- Индексы используются только в операциях сравнения совместимо с операторами = и <=>, с другими операторами, такими как > или < индексирование столбцов не имеет смысла
- Возможно использование только неуникальных индексов.
- Можно использовать записи фиксированной длины, поэтому в них не допустимы столбцы типов TEXT и BLOD.
- В версиях, предшествующих MySQL 4.0.2, не поддерживается индексирование столбцов, содержащих NULL-значения.
Отношения и типы данных
Отношения можно рассматривать как математические наборы, содержащие ряд атрибутов, которые в совокупности представляют собой базы данных и хранимую в ней информацию.
Добавляя запись в таблицу, нужно распределить все её компоненты (атрибуты) по типам данных. Разные реляционные СУБД используют разные типы данных, и они не всегда взаимозаменяемы.
Подобные ограничения (как, например, с типами данных) типичны для реляционных СУБД, ведь, по сути, отношения между данными и строятся на основе ограничений.
Примечание: Базы данных NoSQL не имеют таких строгих ограничений, поскольку они не выстраивают таких отношений между данными. Чтобы узнать больше о NoSQL, читайте эту статью.
Логическое проектирование и оптимизация
OLTP – обработка транзакций в режиме реального времени. Способ организации БД, при котором система работает с небольшими по размерам транзакциями, но идущими большим потоком, и при этом клиенту требуется от системы минимальное время отклика. Примерами OLTP приложений могут быть системы складского учета, системы заказов билетов, банковские системы, выполняющие операции по переводу денег.
Особенности OLTP приложений:
- Транзакций очень много.
- Транзакции выполняются одновременно.
- При возникновении ошибки транзакция должна целиком откатиться и вернуть систему к состоянию, которое было до начала транзакции (не должно быть ситуации, когда деньги сняты со счета, но не поступили на другой счет).
- Все запросы к базе данных, которые должны выполняться в реальном времени, состоят из команд вставки, обновления, удаления.
OLAP системы характеризуются следующими признаками:
- Добавление в систему новых данных происходит относительно редко крупными блоками.
- Данные, добавленные в систему, обычно никогда не удаляются.
- Перед загрузкой данные проходят различные процедуры очистки, связанные с тем, что в одну систему могут поступать данные из многих источников, имеющих различные форматы представления для одних и тех же понятий, данные могут быть некорректны, ошибочны
- Запросы к системе являются нерегламентированными и, как правило, достаточно сложными. Очень часто новый запрос формулируется аналитиком для уточнения результата, полученного при выполнении предыдущего запроса.
- Скорость выполнения запросов важна, но не критична.
BDB (BerkeleyDB)
Таблицы типа BDB обслуживаются транзакционным обработчиком Berkeley DB, разработанным компанией Sleepycat. При создании таблиц данного типа формируются два файла: первый с расширением frm, в котором определяется структура базы данных, а второй с расширением db, в котором размещаются данные и индексы.
Особенности типа BDB:
- Для каждой таблицы ведется журнал. Это позволяет значительно повысить устойчивость базы и увеличить вероятность успешного восстановления после сбоя.
- Таблицы BDB хранятся в виде бинарных деревьев. Такое представление замедляет сканирование таблицы и увеличивает занимаемое место на жестком диске по сравнению с другими типами таблиц. С другой стороны, поиск отдельных значений в таких таблицах осуществляется быстрее.
- Каждая таблица BDB должна иметь первичный ключ, в случае его отсутствия создается скрытый первичный ключ, снабженный атрибутом AUTO_INCREMENT.
- Поддерживаются транзакции на уровне страниц.
- Подсчет числа строк в таблице при помощи встроенной функции count() осуществляется медленнее, чем для MyISAM, так как в отличие от последних, для BDB-таблиц не поддерживается подсчет количества строк в таблице, и MySQL вынужден каждый раз сканировать таблицу заново.
- Ключи не являются упакованными, и ключи занимают больше места.
- Если таблица займет все пространство на диске, то будет выведено сообщение об ошибке и выполнен откат транзакции.
- Для обеспечения блокировок таблиц на уровне операционной системы в файл db в момент создания таблицы записывается путь к файлу. Это приводит к тому, что файлы нельзя перемещать из текущего каталога в другой каталог.
- При создании резервных копий таблиц необходимо использовать утилиту mysqldump или создать резервные копии всех db файлов и файлов журналов. Обработчик таблицы хранит незавершенные транзакции в файлах журналов, их наличие требуется при запуске сервера MySQL.
Формы
Используются в качестве средства для ввода новой информации в таблицу. Преимуществом форм становится их удобный для пользователя вид — разработчик может использовать макет формы или создать совершенно новую. На этот объект можно поместить кнопки, переключатели и многое другое
В числе прочих особое внимание приковывает к себе кнопочная форма, представляющая собой модифицированный диспетчер задач, составляемый пользователем “под себя”. На нее можно поместить основные функции работы с базой данных — вход, выход, заполнение таблиц, просмотр данных
Обычные формы можно также включить в кнопочную.
О языке SQL
SQL — это язык программирования для разработки баз данных. Можно сказать, что это основа всего. Когда только компьютеры появились в продаже, некоторые организации начали переводить базу клиентов в электронный вид. И, естественно, программ таких не было, чтобы создавать базы данных.
Тогда на помощь приходил язык программирования SQL. Вообще, он разрабатывался еще в 1986 году, но массово его начали применять только с 2008 года. Создавать и работать с базами данных на чистом языке SQL довольно-таки неудобно. Весь этот процесс происходит через командную строку, выводится база там же.
Для упрощения создания баз данных появились программы, которые имеют графический интерфейс и практически сами создают запросы на SQL языке. То есть пользователь ничего руками не пишет, лишь создает при помощи функции Drag and drop. Но хочется отметить, что изучение этого языка просто необходимо при разработке больших баз данных. Вы должны понимать, как все это работает, как делаются запросы и прочее.

MyISAM
MyISAM – является родным типом таблиц для базы СУБД MySQL. База данных в MySQL организуется как каталог. Таблицы базы данных организуются как файлы данного каталога. Каждая MyISAM таблица хранится на диске в трех файлах, имена которых совпадают с названием таблицы, а расширение может принимать одно из следующих значений:
- Frm – содержит структуру таблицы, в файле данного типа хранится информация об именах и типах столбцов и индексов.
- Myd – файл, в котором содержатся данные таблицы.
- Myi – файл, котором содержатся индексы таблицы.
Особенности типа таблиц MyISAM:
- Данные хранятся в кросс-платформенном формате, это позволяет переносить базы данных с сервера непосредственным копированием файлов, минуя промежуточные форматы.
- Максимальное число индексов в таблице составляет 64. Каждый индекс может состоять максимум из 16 столбцов.
- Для каждого из текстовых столбцов может быть назначена своя кодировка.
- Допускается индексирования текстовых столбцов, в том числе и переменной длины.
- Поддерживается полнотекстовый поиск.
- Каждая таблица имеет специальный флаг, указывающий правильность закрытия таблиц. Если сервер останавливается аварийно, то при его повторном старте незакрытые флаги сигнализируют о возможных сбойных таблицах, сервер автоматически проверяет их и пытается восстановить.
Отчеты
Отчеты системы управления базами данных необходимы для сбора и предоставления сведений, находящихся в таблицах. Чаще всего эта функция дает возможность получить ответ на какой-нибудь обобщенный вопрос, например, какая сумма была получена от всех клиентов в этом году, купивших какой-то конкретный товар или совершивших покупку в конкретном месте. Все отчеты можно форматировать несколькими способами для возможности предоставления в самом удобном виде.
Эта функция может запускаться в любое время. Каждый раз будут отображаться нужные сведения. Чаще всего отчеты форматируются специально для печати, но могут быть обработаны и для удобства при экранном просмотре.
MongoDB
Самая популярная NoSQL система управления базами данных. Лучше всего подходит для динамических запросов и определения индексов. Гибкая структура, которую можно модифицировать и расширять. Поддерживает Linux, OSX и Windows, но размер БД ограничен 2,5 ГБ в 32-битных системах. Использует платформы хранения MMAPv1 и WiredTiger.
- Разработчик: MongoDB Inc. в 2007
- Написана на C++
- Последняя версия: 4.1.9
- Блог: MongoDB
- Скачать: MongoDB
Особенности
- Высокая производительность.
- Автоматическая фрагментация.
- Работа на нескольких серверах.
- Поддержка репликации Master-Slave.
- Данные хранятся в форме документов JSON.
- Возможность индексировать все поля в документе.
- Поддержка поиска по регулярным выражениям.
Проектирование баз данных
Проектирование — самая трудная задача при работе с данными. Оно заключается не только в том, чтобы создать таблицу, указав наименование столбцов и тип данных. Это гораздо более сложный процесс, требующий специализированных знаний и умений. Говоря о типах баз данных в столбцах, подразумевается, например, способ их записи, который бывает символьный (строковый), числовой, календарный, NULL.
Основная сложность заключается в том, что мощность наших компьютеров ограничена. И пока данных мало, таблиц и строк тоже немного, поэтому машина обрабатывает информацию достаточно быстро. Но с течением времени информации становится всё больше, что может стать причиной снижения быстродействия. Работа машины будет замедляться, времени на обработку запросов потребуется всё больше. Добавить новую запись в таблицу не станет проблемой для реляционной СУБД, а вот выборка данных может превратиться в весьма ресурсоёмкую операцию. Хотя, многое будет зависеть и от настроек СУБД.
MySQL
MySQL работает на Linux, Windows, OSX, FreeBSD и Solaris. Можно начать работать с бесплатным сервером, а затем перейти на коммерческую версию. Лицензия GPL с открытым исходным кодом позволяет модифицировать ПО MySQL.
Эта система управления базами данных использует стандартную форму SQL. Утилиты для проектирования таблиц имеют интуитивно понятный интерфейс. MySQL поддерживает до 50 миллионов строк в таблице. Предельный размер файла для таблицы по умолчанию 4 ГБ, но его можно увеличить. Поддерживает секционирование и репликацию, а также Xpath и хранимые процедуры, триггеры и представления.
- Разработчик: Oracle Corporation
- Написана на C, C++
Особенности
- Масштабируемость.
- Лёгкость использования.
- Безопасность.
- Поддержка Novell Cluster.
- Скорость.
- Поддержка многих операционных систем.








